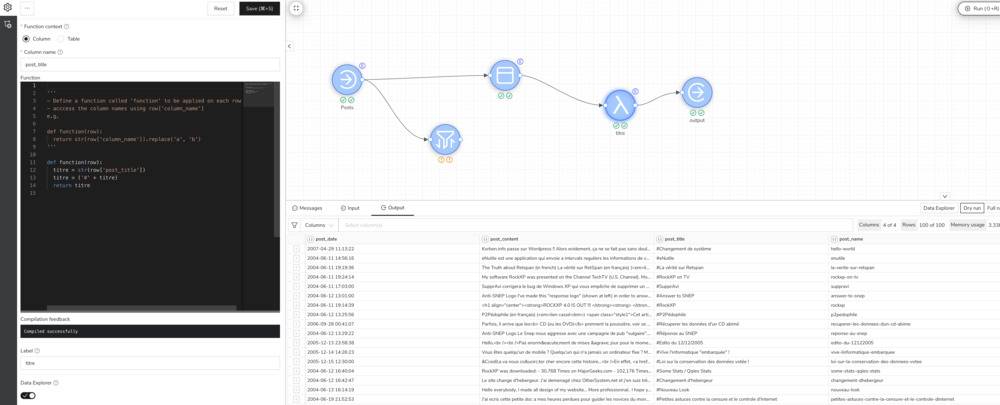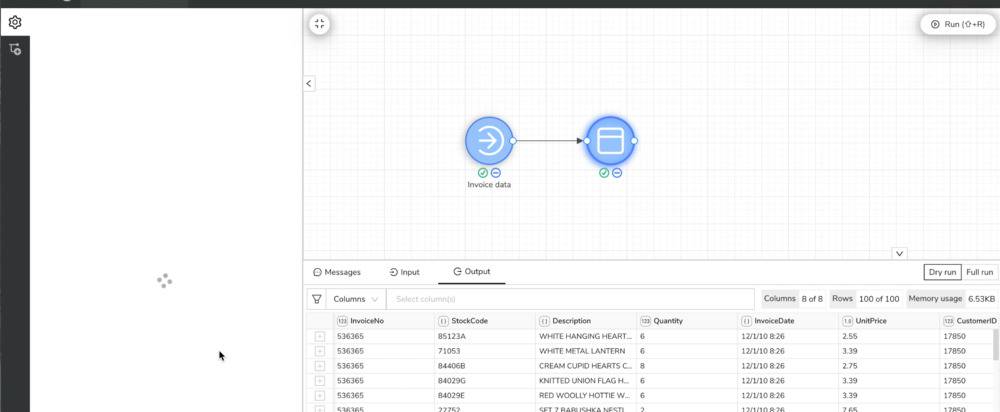
Il arrive parfois qu’on doive retravailler des données. Prendre par exemple un fichier JSON, CSV ou SQL, le filtrer pour enlever des données, retirer certaines colonnes, fusionner plusieurs sources…etc.
La plupart du temps, cela nécessite de savoir développer, car il n’y a pas d’outil magique pour faire ça. Toutefois, voici un outil qui ne réglera pas TOUS vos problèmes, mais qui vous permettra de transformer vos données avec quelques clics en automatisant tout ça pour gagner du temps. C’est d’ailleurs un outil qui aurait pu se retrouver dans le livre de Fabien Olicard qui donne des tas d’astuces pour mieux utiliser son temps et donc en gagner !
Cet outil s’appelle Glue et il fonctionne un peu à la manière d’un Yahoo! Pipes pour ceux qui ont connu cet outil. En gros vous placez une ou plusieurs sources de données, cela peut être une base MySQL, un fichier JSON, un fichier CSV, Excel, SQLite et j’en passe. Ensuite, vous pouvez agréger ces sources de données, concaténer les données, ou les alléger en supprimant des colonnes ou ne ressortir que certaines données avec des opérateurs (is, equal, empty…etc.).
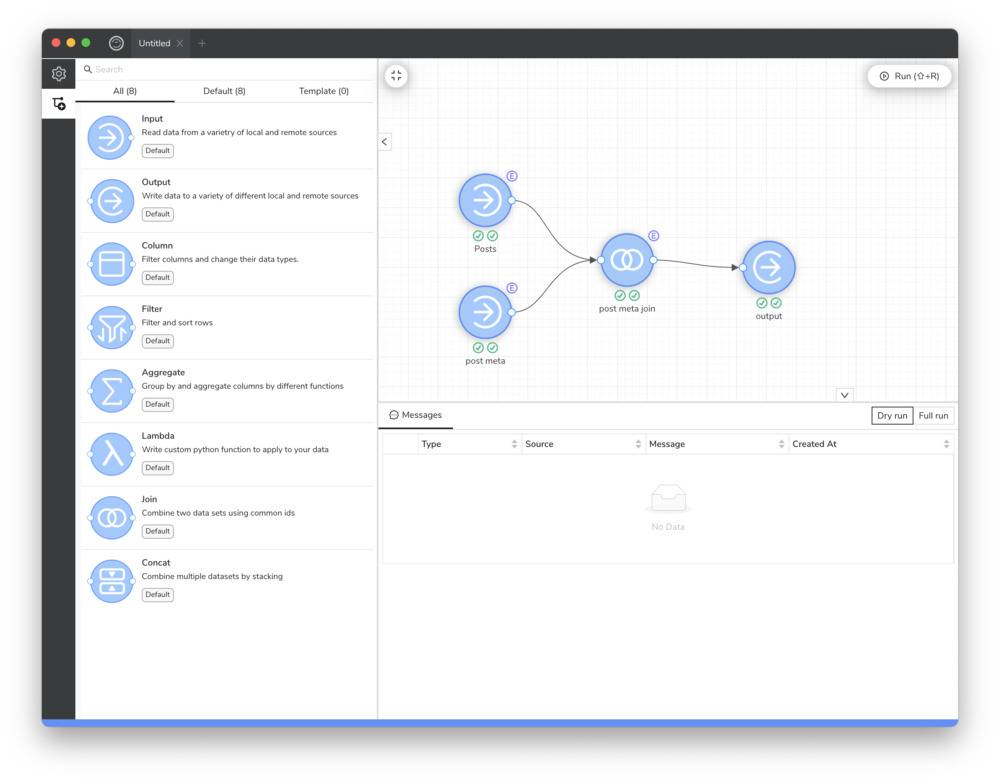
Et une fois que votre tambouille est terminée, vous placez un objet Output et vous choisissez un format de sortie (csv, xls, paquet, feather, sqlite, json).
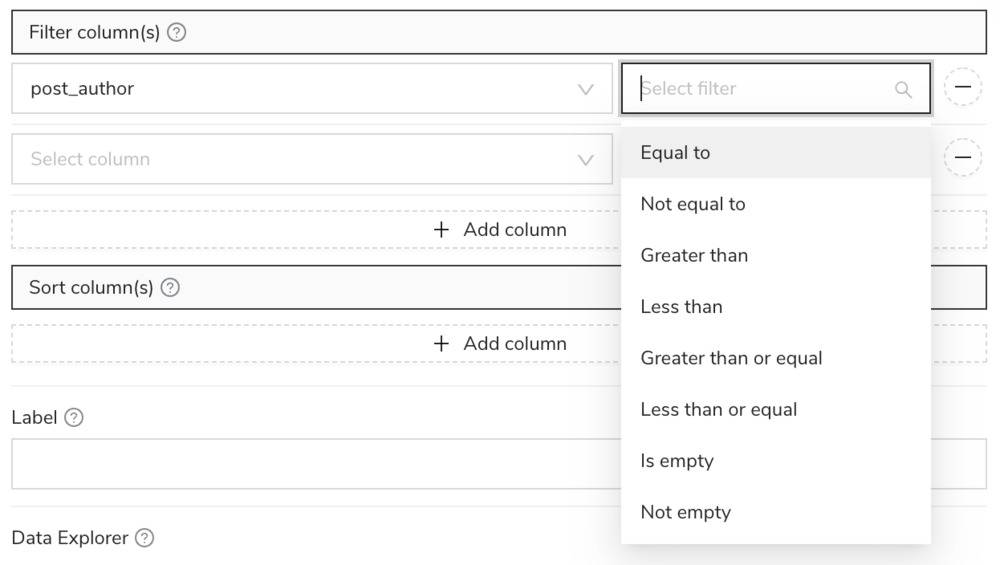
Une fois que le process est en place, y’a plus qu’à cliquer sur Run pour lancer le traitement et obtenir le fichier de sortie de vos rêves.
Les briques essentielles sont là même si on pourrait se trouver limité par rapport à un Yahoo! Pipes mais la bonne nouvelle, c’est que Glue permet d’intégrer également des fonctions en Python. Cela veut dire que vous pouvez également ajouter votre propre couche de traitement fait maison pour modifier les données. C’est super pratique. D’ailleurs, je vous recommande ce livre pour ceux qui veulent se mettre au Python, un langage simple à apprendre et vraiment hyper puissant.

Vraiment top !