
DeepCoder-14B - L'IA open source qui défie OpenAI o3 en coding
Vous en avez marre de payer une fortune pour ChatGPT juste pour qu’il vous génère du code que vous auriez pu écrire vous-même ?
Et en même temps, c’est quand même cool de diviser par deux ou trois votre temps de dev avec un assistant IA. Mais ce qui serait encore plus cool c’est d’en avoir un aussi puissant que les solutions commerciales, mais entièrement gratuit et surtout qui respecte votre vie privée !
Alors si vous êtes développeur et que vous vous retrouvez à jongler entre Stack Overflow, GitHub et la doc officielle pour chaque fonction que vous écrivez, cet article va bien vous aider !
Développé par Together AI et Agentica, DeepCoder-14B s’inscrit dans cette nouvelle vague de modèles de taille moyenne qui rivalisent avec les mastodontes aux centaines de milliards de paramètres. Et les résultats sont bluffants puisque sur LiveCodeBench (LCB), il atteint un score de 65.4, à seulement 3.2% sous le score d’o3-mini qui nécessite pourtant 5 fois plus de ressources de calcul.
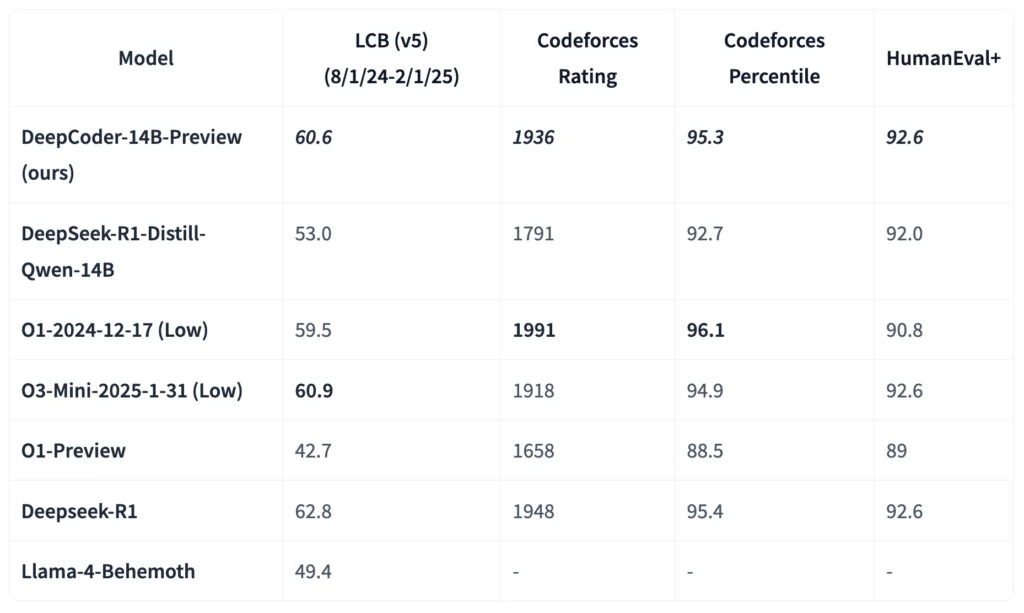

Voici ses specs :
- 14 milliards de paramètres seulement (vs les centaines de milliards pour GPT-4)
- Il fonctionne sur un serveur avec des GPU de gamme moyenne
- Un temps d’inférence plus rapide, moins de latence
- Et des coûts de déploiement divisés par 10 ou plus
Ce modèle est, d’après ses concepteurs, particulièrement efficace pour des tâches comme la refactorisation, la génération de tests unitaires, et l’optimisation de performance…. Des domaines où son entraînement spécifique au code lui donne un avantage par rapport aux modèles généralistes.
Et surtout, ça veut dire qu’un développeur indépendant peut désormais faire tourner un assistant de coding de niveau pro sur sa propre machine, sans vendre un rein pour payer des API ou craindre que son code propriétaire ne finisse dans le dataset d’entraînement du prochain modèle commercial.
En plus d’être performant, il est totalement transparent car l’équipe a partagé non seulement le modèle, mais aussi tout le processus d’entraînement et contrairement aux maths où les problèmes et solutions de qualité pullulent, entraîner une IA uniquement sur du code c’est pas simple.
Comment récompenser correctement le modèle sans qu’il ne triche en mémorisant des solutions ? Ou comment gérer les longues séquences de raisonnement nécessaires pour résoudre des problèmes complexes ?
L’équipe derrière DeepCoder a résolu ces challenges avec plusieurs innovations clés telles que :
1. Une curation de données chirurgicale :
Ils ont mis en place un pipeline qui filtre rigoureusement 24 000 problèmes de programmation pour garantir validité, complexité et absence de duplication. C’est cette qualité des données qui forme la fondation solide de DeepCoder.
2. Une fonction de récompense sans fioritures :
Pas de récompenses partielles ou de métriques complexes… le modèle reçoit un signal positif uniquement si son code passe tous les tests unitaires dans un temps limité. Cette approche brutale mais efficace force le modèle à vraiment comprendre et résoudre les problèmes, plutôt que de chercher des raccourcis.
3. GRPO+ (Group Relative Policy Optimization) :
Une version améliorée de l’algorithme qui a fait le succès de DeepSeek-R1, avec des modifications pour une stabilité accrue pendant les longues sessions d’entraînement. Résultat, le modèle continue à s’améliorer là où d’autres stagnent.
4. Extension contextuelle progressive :
Et là, c’est comme entraîner un athlète d’abord sur des sprints courts, puis progressivement sur des distances plus longues, ce qui lui permet finalement de courir un marathon tout en gardant la vitesse d’un sprinteur. Concrètement, ils ont d’abord entraîné le modèle sur des séquences courtes, puis progressivement augmenté la taille du contexte de 16K à 32K tokens. Et cerise sur le gâteau, le modèle final peut gérer jusqu’à 64K tokens, donc de quoi traiter des problèmes vraiment complexes.
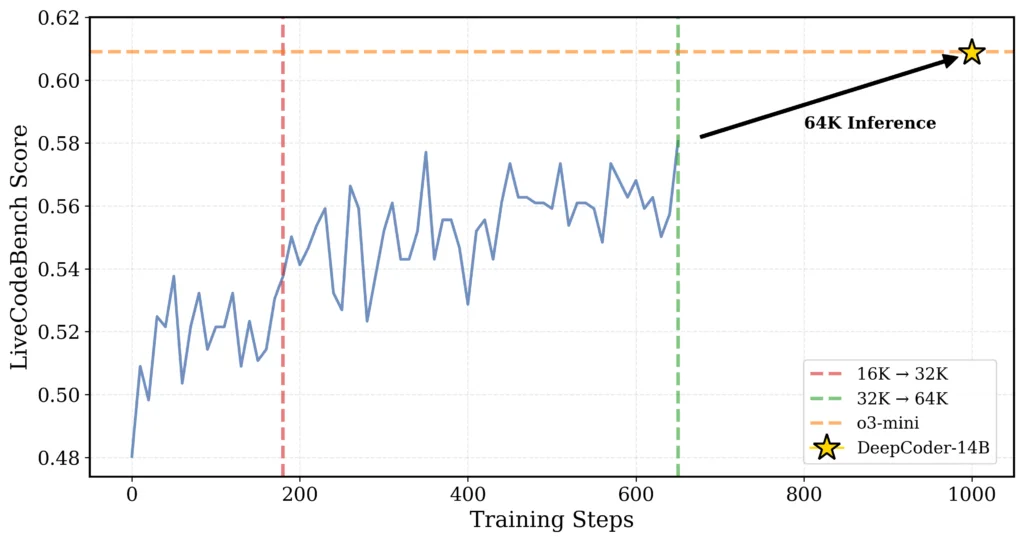
La technique la plus impressionnante, c’est le “One-Off Pipelining”, qui a permis d’accélérer l’entraînement jusqu’à 2x en réorganisant intelligemment les étapes d’échantillonnage et de mise à jour du modèle. Sans cette optimisation, l’entraînement aurait pris 5 semaines au lieu de 2,5 sur 32 GPU H100.
Et pour les nerds du deep learning : oui, tout le code de ces optimisations est disponible sur GitHub. C’est Noël avant l’heure les amis !!!
Voilà, on a connu LLaMA, Mistral, DeepSeek… mais DeepCoder-14B pousse l’ouverture du code encore plus loin car voici ce qui est réellement partagé en open source :
- Le modèle complet et ses poids (sur Hugging Face)
- L’ensemble des 24 000 problèmes d’entraînement filtrés
- Le code d’entraînement et les logs complets (même les erreurs !)
- Les optimisations système comme verl-pipeline
Tout ça sous licence très permissive, ce qui signifie que vous pouvez l’utiliser, le modifier, et même l’intégrer dans des projets commerciaux, sans payer un centime. L’impact est donc massif pour différents acteurs de l’écosystème. Pour les chercheurs, c’est l’accès sans précédent à un modèle RL (apprentissage par renforcement) de pointe et son processus complet. Bref, une mine d’or pour comprendre et améliorer les techniques d’IA.
Maintenant pour les développeurs que nous sommes, c’est surtout un assistant de dev de niveau pro, gratuit, qui peut tourner localement sans fuite de données et pour les entreprises, c’est également une alternative viable aux API coûteuses, avec la possibilité de fine-tuner le modèle sur leur propre base de code. Par exemple, pour une équipe de 10 développeurs, le passage à DeepCoder-14B peut représenter une économie de 1200€ à 2400€ par an par rapport aux solutions API payantes, tout en offrant un contrôle total sur les données.
Alors, maintenant, comment mettre ce petit bijou entre vos mains tremblantes d’excitation ???
Et bien l’une des meilleures façons d’intégrer DeepCoder-14B à VS Code est d’utiliser l’extension Continue, qui permet d’utiliser facilement des modèles locaux pour l’assistance au code.
Assurez vous quand même d’avoir :
- Une carte graphique avec au moins 24Go de VRAM (idéalement une NVIDIA RTX 3090 ou supérieure) ou un bon gros Mac M3 / M4.
- 16Go de RAM système minimum (32Go recommandés)
- Au moins 10Go d’espace disque disponible pour le modèle
Ensuite, vous installez cette extension + ollama, puis via un terminal, vous chargez Deepcoder comme ceci dans Ollama :
ollama run deepcoder:14b
Puis dans Visual Studio Code ou l’un de ses dérivés, vous choisissez comme modele de chat Ollama en autodetect. Et dans la liste, vous devriez voir tous les modèles que vous avez installé dont Deepcoder 14B.
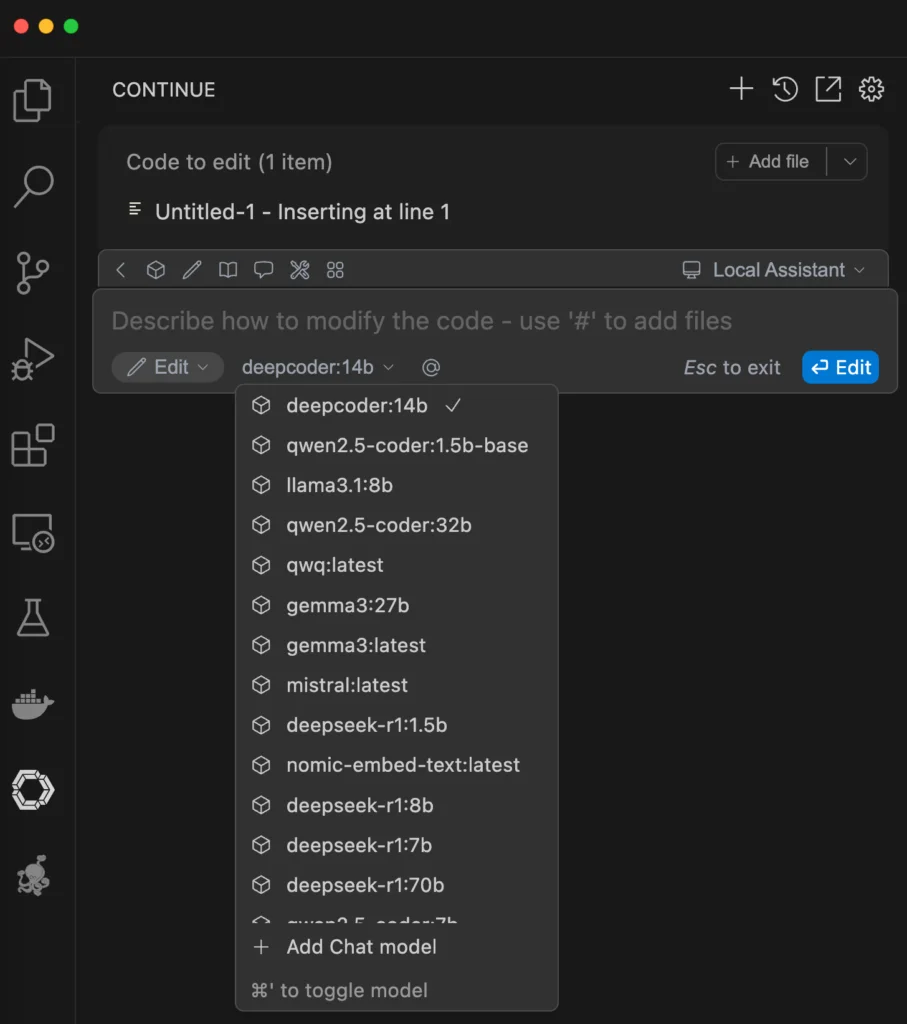
Et voilà, à vous le vibe coding comme on dit…
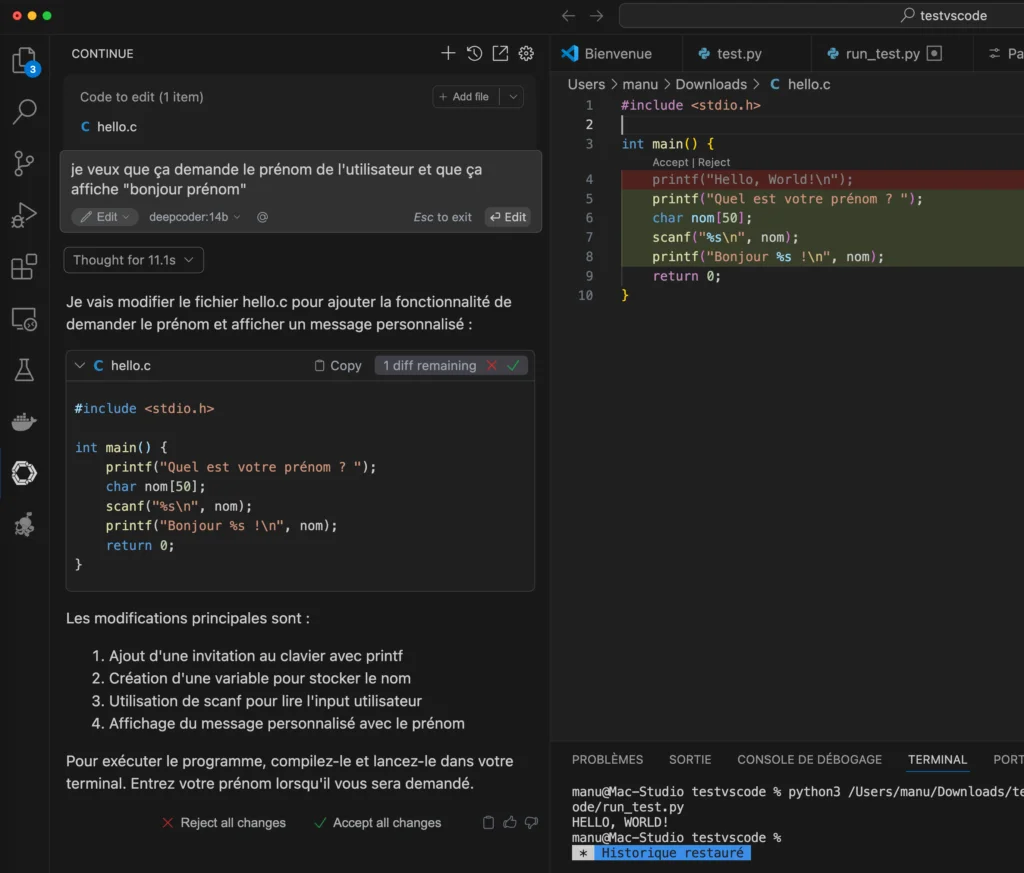
Bien sûr, DeepCoder a aussi ses limites… Pas de capacités multimodales (comme l’analyse d’images de code), une connaissance limitée aux données d’entraînement, et encore quelques difficultés sur certains problèmes très complexes mais honnêtement, pour du 100% gratuit et local, c’est déjà exceptionnel.
En combinant des performances au top, une taille raisonnable et une approche totalement open source, DeepCoder-14B ouvre ainsi la voie à une nouvelle ère où l’IA de pointe n’est plus réservée aux géants de la tech… Et pour les développeurs que vous êtes, c’est l’occasion parfaite pour reprendre le contrôle de leurs outils d’IA sans compromettre la qualité de leur code ou la confidentialité de leurs projets.
Vous êtes développeur web ? Alors vous allez adorer l'Offre Unique de o2switch, conçue spécialement pour vous !

Profitez d'une puissance inégalée avec 12 threads CPU et 48 Go de RAM pour des performances à couper le souffle. Déployez vos projets en quelques clics grâce à Softaculous et ses + de 300 scripts prêts à l'emploi.
La vitesse, vous aimez ? Eux aussi ! C'est pour ça qu'ils vous font fait profiter de la technologie NVMe dernière génération et de puissants caches comme Varnish et LiteSpeed. Tout ça avec la sérénité d'un hébergement français sécurisé par un WAF sur-mesure et un support technique toujours à vos côtés.
Et vous savez quoi ? Tout ça est à vous pour seulement 4,2 € HT/mois. Foncez, c'est le moment de coder sans limites et de donner vie à vos projets les plus fous grâce à o2switch !