
Un outil en ligne de commande pour extraire des données depuis du HTML
Par le passé, j’ai déjà évoqué la commande jc au détour d’un article. Pour rappel, jc permet de transformer des données textuelles provenant de commandes ou de scripts en données structurées de type JSON.
Et aujourd’hui, j’aimerais vous parler de htmlq qui reprend le principe de fonctionnement de jq sauf que là, on bosse sur de la donnée structurée en HTML. L’outil permet ainsi de sélectionner et extraire des éléments d’un fichier HTML en utilisant des sélecteurs CSS.
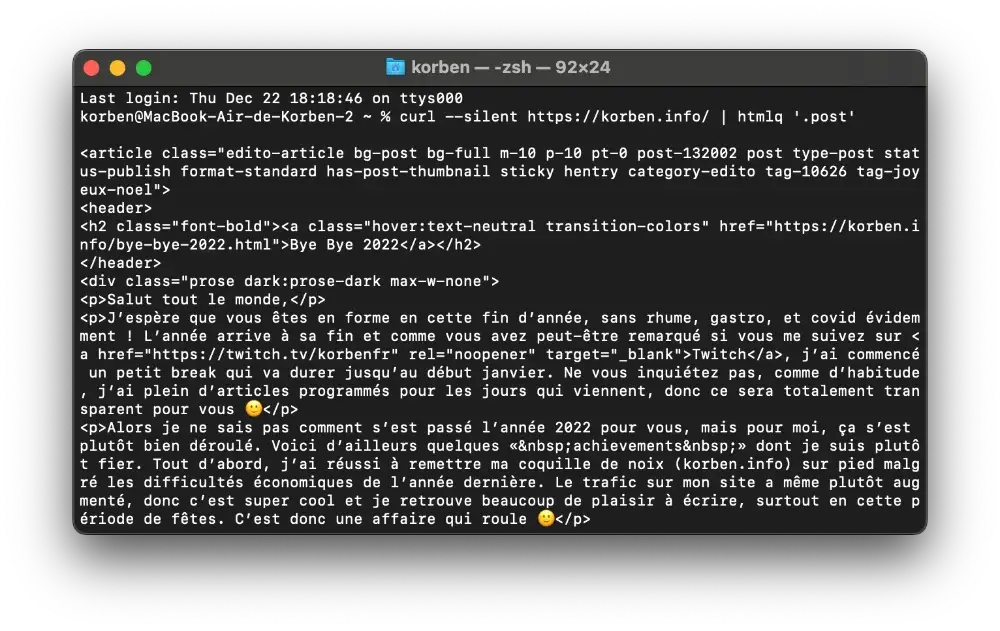
Histoire que vous captiez mieux, voici un exemple permettant de récupérer le HTML contenu dans un élément dont la classe est .post :
curl --silent https://korben.info/ | htmlq '
```.post```
'

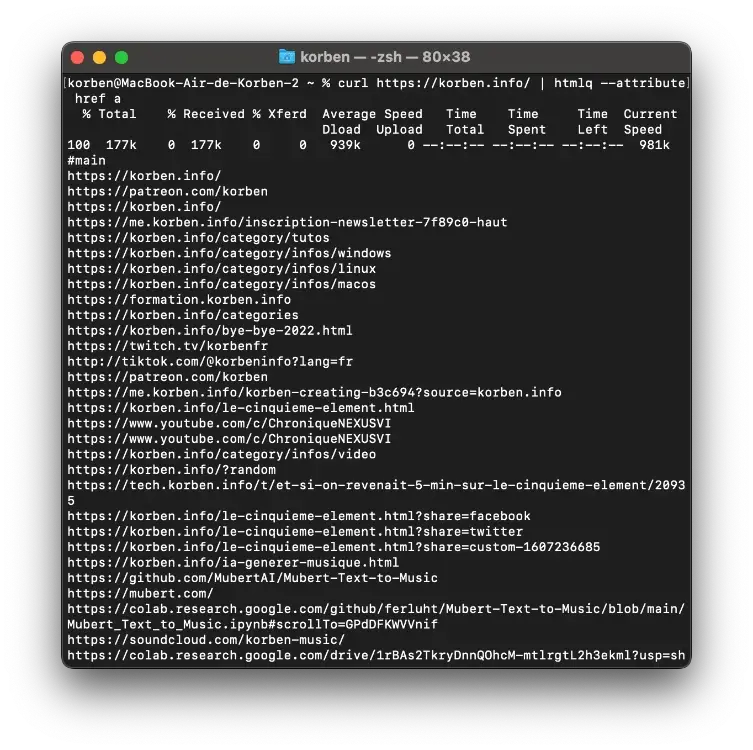
Par exemple pour sortir tous les liens d’une page :
curl https://korben.info/ | htmlq --attribute href a
Ou encore pour récupérer uniquement un format textuel (sans les balises HTML) :
curl --silent https://korben.info | htmlq --text .post

Cela permet de faire beaucoup de choses assez facilement sans forcément avoir à coder un truc pour jouer avec les XPath.
Maintenant pour install htmlq, ça dépend de votre OS :
Cargo :
cargo install htmlq
FreeBSD :
pkg install htmlq
Homebrew (macOS) :
brew install htmlq
Scoop (Windows) :
scoop install htmlq
Pour tous les détails, je vous invite à lire la doc sur Github.
Vous en avez assez d'être bridé par les restrictions de votre hébergeur actuel ? Il est temps de passer à la vitesse supérieure !
L'Offre Unique de o2switch est LA solution pour libérer enfin tout votre potentiel créatif.

Un espace disque illimité pour stocker tous vos projets, des bases de données à volonté pour gérer vos données sans contrainte, et une bande passante sans limites pour faire face à n'importe quel pic de trafic. Tout ça, à portée de clic grâce à l'interface cPanel ultra intuitive, même si vous débutez. Installez WordPress, gérez vos emails, déployez vos outils... en toute simplicité !
Et comme votre tranquillité d'esprit est primordiale, o2switch héberge vos données en France, avec un support 24/7 et des sauvegardes quotidiennes pour ne rien laisser au hasard. Cerise sur le gâteau : votre nom de domaine est offert !
Vous hésitez encore ? Avec la promo actuelle, l'Offre Unique passe à seulement 4,2 € HT/mois. C'est le moment de sauter le pas et de donner vie à tous ces projets que vous rêvez de réaliser. Votre futur vous créatif vous remercie déjà !