
J'ai testé la nouvelle génération d'images avec GPT-4o et c'est un autre monde
Bon, je suis content, OpenAI s’est enfin sorti les doigts pour nous proposer un système de génération d’images qui tient la route. Alors bien sûr, on est encore loin de la qualité “photo” de Midjourney ou de Flux 1.1 Pro mais pour faire des logos ou des schémas, ça a l’air top ! Surtout qu’il sait écrire presque sans erreur. Trop cool !!
Ces images typées DALL-E 3 avec des hiéroglyphes en guise de texte, c’est enfin terminé ! Youpi ! En effet, Sam Altman, le CEO d’OpenAI, a annoncé en grande pompe l’intégration native de la génération d’images directement dans ChatGPT via leur modèle multimodal GPT-4o.
Traduction pour ceux qui comprennent vite quand on leur laisse beaucoup de temps, vous pouvez maintenant demander à ChatGPT de créer des images directement dans la conversation, sans passer par un outil externe. Super pratique pour itérer rapidement sur une idée d’image.
Ce qui rend cette mise à jour très intéressante, c’est que GPT-4o remplace complètement DALL-E 3 comme modèle par défaut de génération d’images et contrairement à son prédécesseur, il excelle dans la création d’images contenant du texte lisible. Fini les abus textuels !
Le modèle prend un peu plus de temps pour générer, mais la qualité en vaut la peine… Côté technique, cette évolution est le fruit d’une année entière de travail avec une centaine de “formateurs humains” qui ont étiqueté les données d’entraînement, pointant notamment les erreurs dans les textes et les déformations anatomiques (ces fameuses mains à 8 doigts qu’on connaît trop bien). Cette technique, appelée Reinforcement Learning from Human Feedback (RLHF), a ainsi permis d’affiner considérablement les performances du modèle.

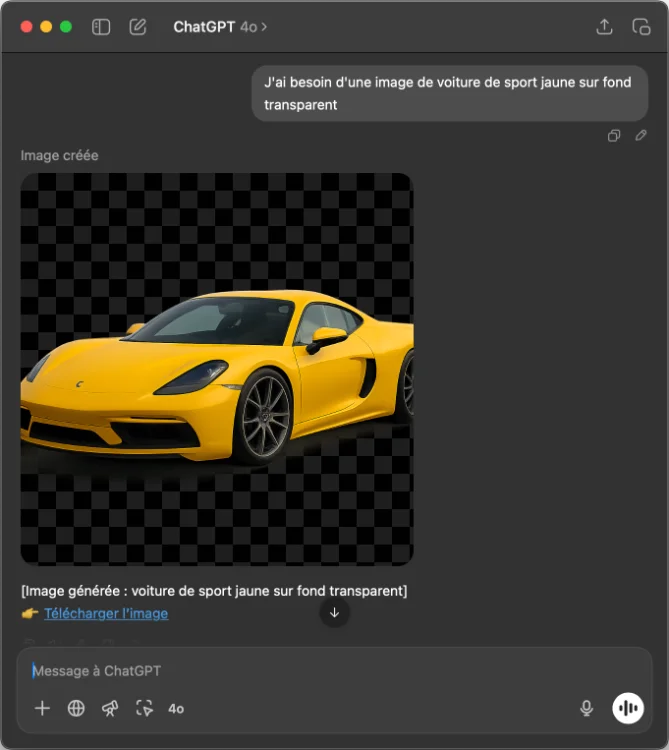
Parmi les fonctionnalités qui m’ont tapé dans l’œil, il y a par exemple la possibilité de créer des images avec des arrière-plans transparents (parfait pour les logos)…
L’utilisation de codes HEX pour des couleurs précises…

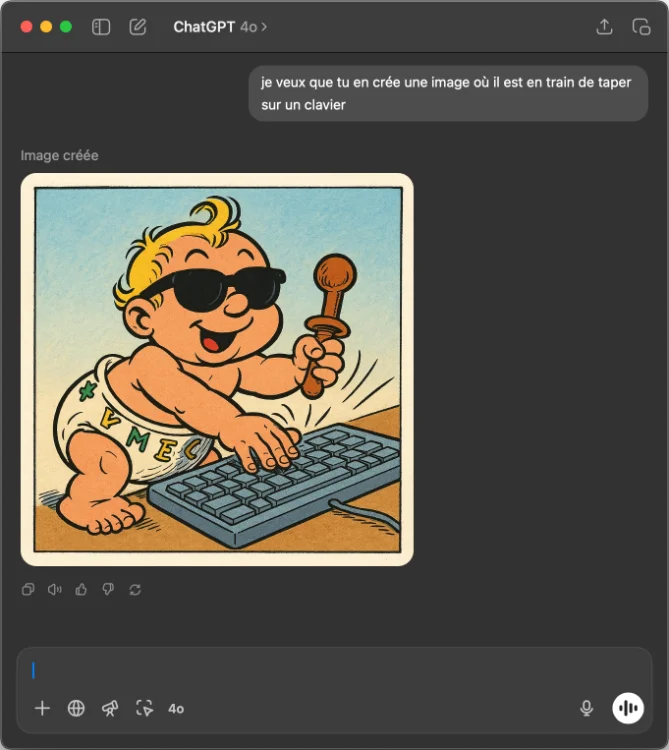
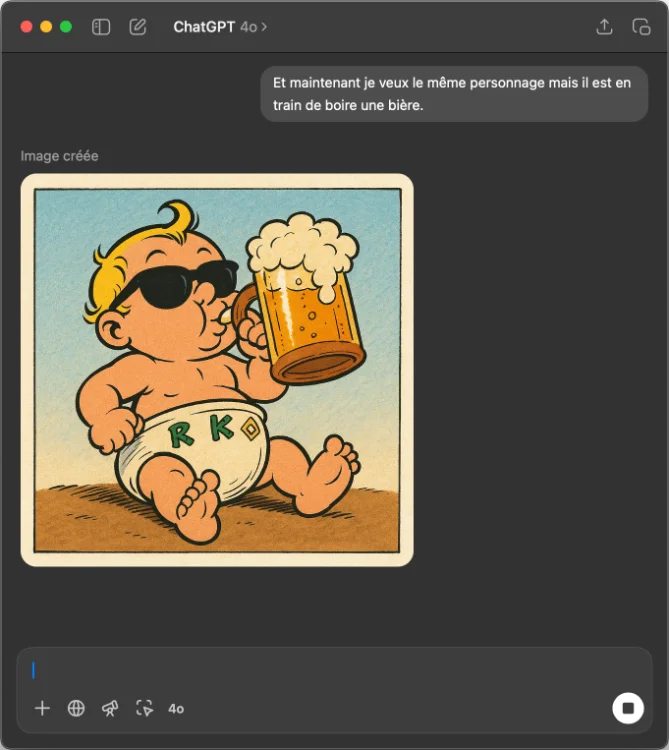
Et surtout la capacité à maintenir une cohérence visuelle sur plusieurs itérations. Comme ça si vous concevez un personnage pour un jeu vidéo ou une BD, vous pouvez désormais affiner progressivement son apparence sans perdre les caractéristiques de base.
Niveau photo réalisme voici le meilleur truc que j’ai pu obtenir en lui donnant un look Polaroïd des années 80. C’est loin de Midjourney comme je le disais mais ça peut faire illusion.


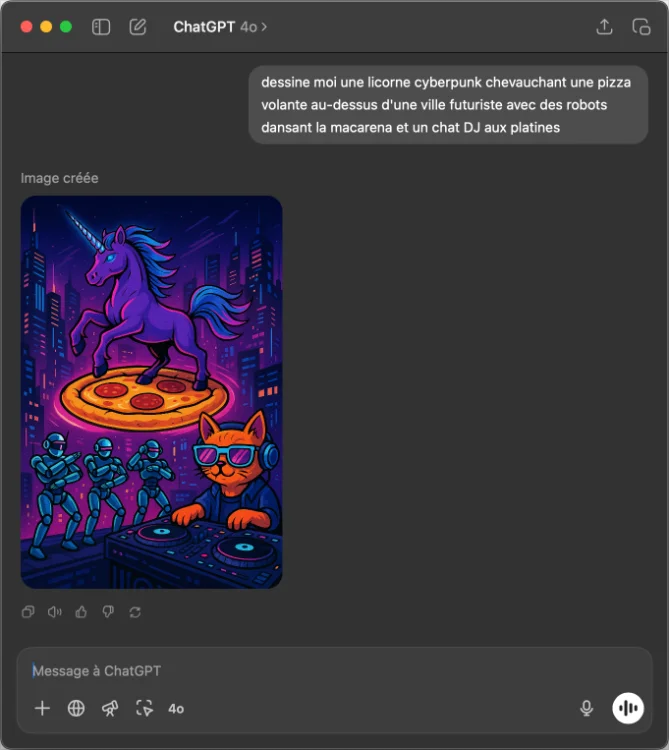
Le modèle est également capable de gérer des instructions complexes avec 10 à 20 objets différents dans une même image. C’est-à-dire que vous pouvez lui demander de dessiner “une licorne cyberpunk chevauchant une pizza volante au-dessus d’une ville futuriste avec des robots dansant la macarena et un chat DJ aux platines” et il s’en sortira plutôt bien. J’ai testé. C’est flippant.
Autre nouveauté qui va faire faire crier les plus prudes d’entre vous, OpenAI a assoupli ses restrictions de contenu. En effet, Sam Altman a déclaré que GPT-4o pourra créer des contenus “offensants” dans une “mesure raisonnable”, mettant ainsi en avant la “liberté intellectuelle” des utilisateurs. On est encore loin de la permissivité de Grok d’Elon Musk, mais c’est un pas dans cette direction.
Rassurez-vous (ou pas), les gardes-fous restent en place pour les contenus vraiment problématiques comme la pédopornographie ou les deepfakes sexuels. D’ailleurs la génération de cette affiche a été interrompue… snif, on ne saura jamais ce que ça représentait.
Côté accessibilité, c’est là que ça devient vraiment intéressant ! La fonction est disponible pour tous, même avec un compte gratuit ! Les utilisateurs Plus, Pro et Team y ont accès immédiatement, tout comme les utilisateurs gratuits. Seuls les comptes Enterprise et Education devront patienter un peu, tandis que les développeurs qui voudraient l’intégrer via l’API devront attendre quelques semaines. Cette stratégie d’OpenAI est assez maline puisqu’ils démocratisent l’accès à leurs meilleurs outils pour rattraper leur retard sur la concurrence.
Maintenant, si vous avez toujours la nostalgie de DALL-E 3, vous pourrez toujours y accéder via un GPT dédié mais franchement, après avoir testé GPT-4o, je ne vois pas pourquoi vous voudriez revenir en arrière.
Pour l’essayer, rien de plus simple, connectez-vous à ChatGPT et demandez-lui de créer une image. Voici quelques prompts que j’ai testés avec de bons résultats :
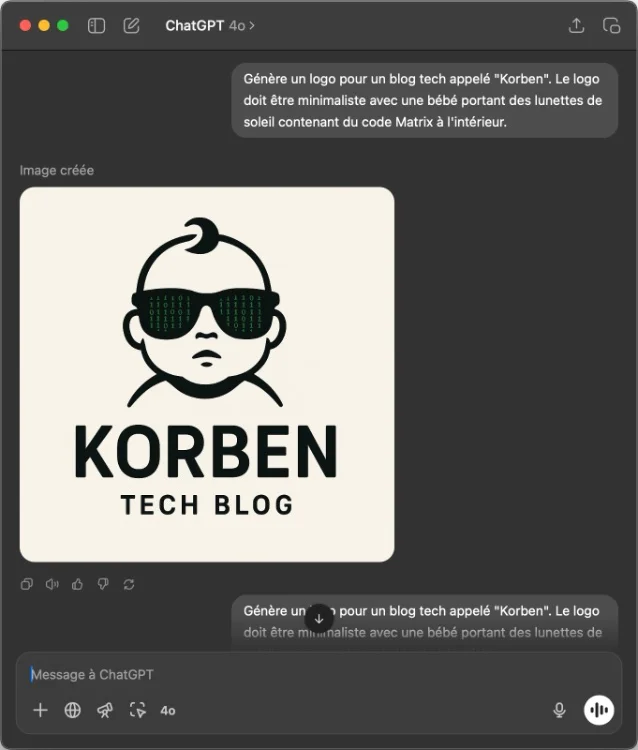
Génère un logo pour un blog tech appelé “Korben” avec un fond transparent. Le logo doit être minimaliste avec une bébé portant des lunettes de soleil contenant du code Matrix à l’intérieur.
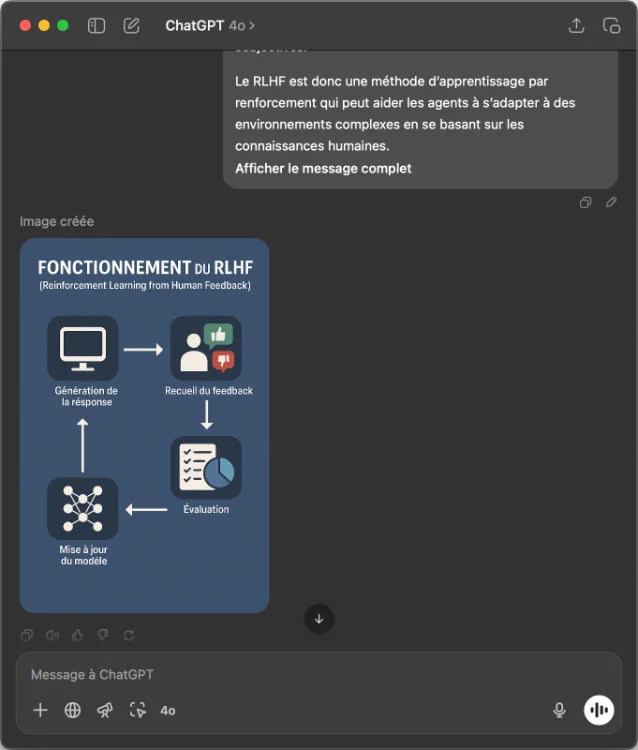
Crée une infographie expliquant le fonctionnement du RLHF dans l’IA, avec du texte lisible et un design moderne sur fond bleu foncé code hexa #556D8D
Bref, je pense que je vais l’utiliser dans mon boulot car pour pour faire un schéma ou une petite image pour illustrer un article sur un logiciel, c’est top !
Alors oui, je sais, GPT-4o n’est pas parfait. J’ai remarqué qu’il galère encore avec les proportions et certains détails anatomiques complexes. Il prend aussi plus de temps que DALL-E 3 pour générer ses images. Mais pour un outil intégré directement dans ChatGPT, c’est un bond en avant impressionnant. OpenAI rattrape enfin son retard face à Google Gemini qui proposait déjà la génération d’images depuis mi-2024.
Comme ça, plus besoin de jongler entre ChatGPT et Midjourney pour vos projets créatifs ! Enfin… à moins que vous ne visiez une qualité vraiment photo realiste, auquel cas Midjourney garde encore une longueur d’avance. Mais pour tout le reste, GPT-4o semble très prometteur. Adieu les mains difformes et les textes illisibles et bonjour aux heures passées à générer des images de chats astronautes en train de manger des pizzas sur Mars. Ne me remerciez pas pour votre future perte de productivité.
A découvrir ici : https://chat.openai.com
Vous êtes développeur web ? Alors vous allez adorer l'Offre Unique de o2switch, conçue spécialement pour vous !

Profitez d'une puissance inégalée avec 12 threads CPU et 48 Go de RAM pour des performances à couper le souffle. Déployez vos projets en quelques clics grâce à Softaculous et ses + de 300 scripts prêts à l'emploi.
La vitesse, vous aimez ? Eux aussi ! C'est pour ça qu'ils vous font fait profiter de la technologie NVMe dernière génération et de puissants caches comme Varnish et LiteSpeed. Tout ça avec la sérénité d'un hébergement français sécurisé par un WAF sur-mesure et un support technique toujours à vos côtés.
Et vous savez quoi ? Tout ça est à vous pour seulement 4,2 € HT/mois. Foncez, c'est le moment de coder sans limites et de donner vie à vos projets les plus fous grâce à o2switch !