
Llama 4 - J'ai testé le nouveau modèle IA de Meta
Mark Zuckerberg, qui doit bien avoir les boules d’avoir soutenu Trump, essaye de noyer son chagrin dans l’élevage de Lamas. Alors pas des lamas idiots qui chiquent aussi bien que votre belle mère mais plutôt des Lamas numériques à savoir les fameux LLM de Meta, qui pourraient bien révolutionner vos projets persos avec leur nouvelle approche !
Il vient donc d’annoncer la mise à disposition de Llama 4, leur nouveau modèle multi-modal (Il peut comprendre le texte et les images) qui a été entrainé sur près de 30 milliards de tokens (soit + du double de Llama 3) et dispose d’un contexte de 10 millions de tokens. En gros, c’est comme lui passer l’équivalent de 8 000 pages de texte, soit la Bible complète + l’intégralité de la trilogie du Seigneur des Anneaux + le manuel d’utilisation de votre micro-ondes, et il se souviendra de tout en même temps.
Dispo en 2 versions, c’est le premier modèle à utiliser l’architecture MoE (Mixture of Expert). Il s’agit d’un mode de fonctionnement qui divise les tâches en sous problème, ce qui permet d’activer uniquement les parties nécessaires du modèle sur chaque tâche spécifique.
La version Scout, c’est celle que je viens de tester à l’instant. C’est :
- 17 milliards de paramètres actifs avec 16 experts (Les MoE)
- 109 milliards de paramètres au total
- Il tient sur un seul GPU NVIDIA H100 (avec quantification Int4)
- Dispose d’une fenêtre de contexte de 10 millions de tokens
- Et est très orienté efficacité et performances optimisées
L’autre modèle, Maverick est encore plus balèze mais destiné à concurrencer carrément des modèles comme GPT 4o ou Gemini 2.0 Flash.
- 17 milliards de paramètres actifs avec 128 experts
- 400 milliards de paramètres au total
- Il tient également sur un seul GPU NVIDIA H100
- Et comme je le disais, il a des performances comparables aux modèles haut de gamme
Ces modèles sont dispo en téléchargement chez Meta et HuggingFace si vous avez une machine assez puissante pour l’essayer, mais vous pouvez également les tester via Whatsapp, Messenger, Instagram Direct Messenger ou directement sur le site de Meta.ai. Et c’est gratuit !
![]()
Pour ma part, sur mon Mac Studio M4, j’ai réussi à faire tourner Scout, à la vitesse de 39 tokens / secondes. Je suis content, c’est plutôt rapide, et je vais pouvoir utiliser ce modèle dans mes projets dev de conquête du monde ! Pour vous donner une idée, j’ai pu générer une réponse complète de 569 mots à une question sur l’histoire de la Super Nintendo en moins de 20 secondes. Et ça, c’est sur du matériel grand public, pas sur un supercalculateur.
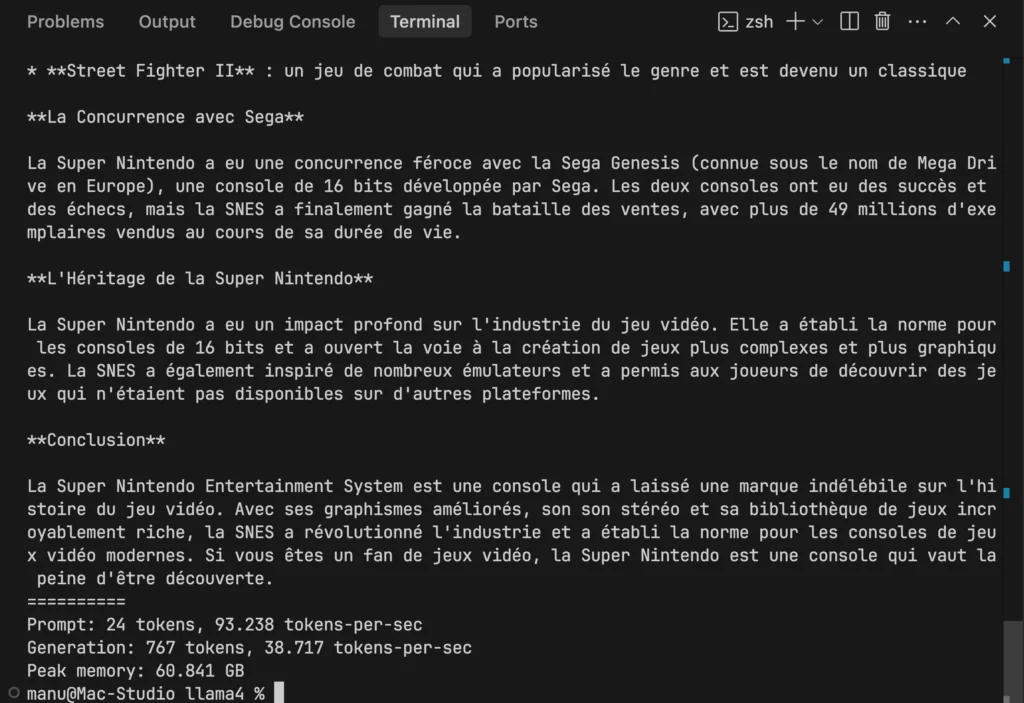
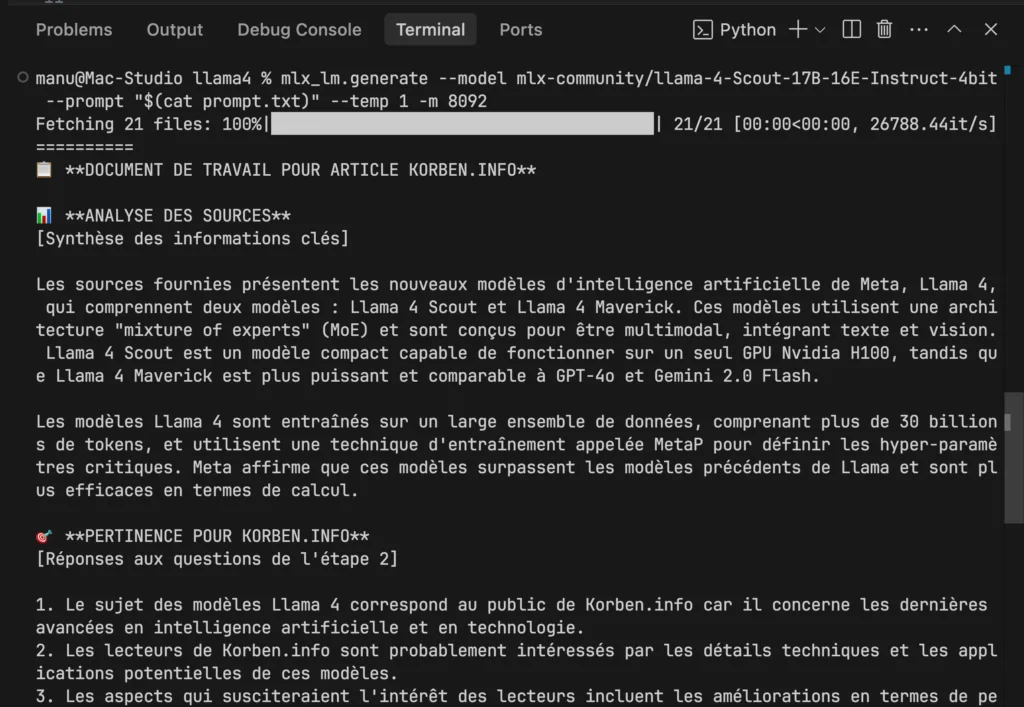
Si vous voulez tester ça, il vous faudra installer mlx-lm avec pip et lancer cette commande :
mlx_lm.generate --model mlx-community/llama-4-Scout-17B-16E-Instruct-4bit --prompt "Combien fait 3+2 ?" --temp 1 -m 4096
J’ai tenté Maverick aussi mais en vain (c’était prévisible…)
Ce qui est vraiment intéressant avec ces nouveaux modèles, c’est ce truc de Mixture of Experts (MoE) car ça permet de réduire drastiquement les calculs nécessaires pour une réponse, ça réduit donc les coûts, ça permet d’avoir une latence plus faible et surtout dans le futur, ça va permettre à Meta de créer des modèles plus grands (plus intelligents quoi…) avec les mêmes ressources. Et ça c’est beau !
Avec une telle fenêtre de contexte, vous pourriez lui faire analyser l’intégralité du code source d’un projet complexe, traiter plusieurs documents scientifiques à la fois, ou même lui faire résumer tous tes e-mails des 6 derniers mois en une seule requête. Fini les API hors de prix et les données qui partent on ne sait où. Avec Scout sur votre Mac (ou un PC avec ce qui faut dans le ventre), vous gardez toutes vos données sensibles à la maison ou en entreprise tout en ayant des performances qui rivalisent avec les solutions cloud.
D’ailleurs, ils ont bientôt prévu Llama 4 Behemoth, ce qui va faire plaisir aux sataniques, et qui lui disposera de 288 milliards de paramètres actifs pour 16 experts. Soit près de 2 000 milliards de paramètres au total ! C’est dingue ! Ce modèle est même utilisé pour enseigner aux autres modèles Llama 4 grâce à des techniques de distillation. Sur le papier, il surpasserait donc GPT-4.5, Claude Sonnet 3.7 et Gemini 2.0 Pro (benchmark STEM).
Llama 4 est donc typiquement le genre de modèle qui va vous permettre d’écrire, de coder ou de faire de l’analyse d’images et de documents 100% en local, pour peu que vous ayez le hardware approprié. Par contre, Meta a mis en place une licence restrictive sur son modèle, ce qui fait que c’est présenté comme de l’open source mais ça n’en est pas du tout. Autre sujet qui fait débat aussi, c’est que les données d’entrainement de ces modèles auraient contenu des œuvres piratées (livres…etc). A voir aussi s’il est neutre politiquement ou si Llama 4 soutien Trump ^^.
Bref, c’est un bon modèle quand même parce qu’il permet un accès à un LLM puissant / intelligent tout en ménageant les ressources en matériel et en énergie. Si vous êtes développeur, je vous invite vraiment à le tester et à me dire en commentaires ce que vous en pensez.
Vous cherchez un hébergement web professionnel pour propulser votre entreprise ? Ne cherchez plus.

Avec l'Offre Unique de o2switch, offrez à votre TPE/PME l'hébergement qu'elle mérite pour viser les sommets.
Boostez la vitesse de votre site et vos applications avec 12 CPU et 48 Go de RAM. Stockez sans compter grâce à l'espace disque illimité. Soyez serein avec des sauvegardes quotidiennes automatiques et un support technique toujours disponible. Tout ça sur des serveurs sécurisés, hébergés en France.
Pilotez votre activité en ligne du bout des doigts, sans connaissances techniques, via l'interface cPanel. Site web, outils, emails... tout est centralisé !
Le meilleur dans tout ça ? L'Offre Unique est à seulement 4,2 € HT/mois. C'est le moment d'offrir à votre entreprise l'hébergement qu'elle mérite pour décoller. Avec o2switch, dites adieu aux problèmes techniques et bonjour à la croissance !