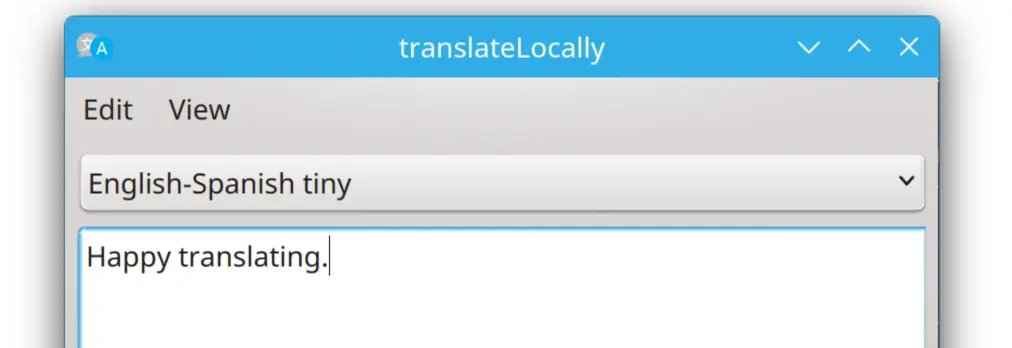
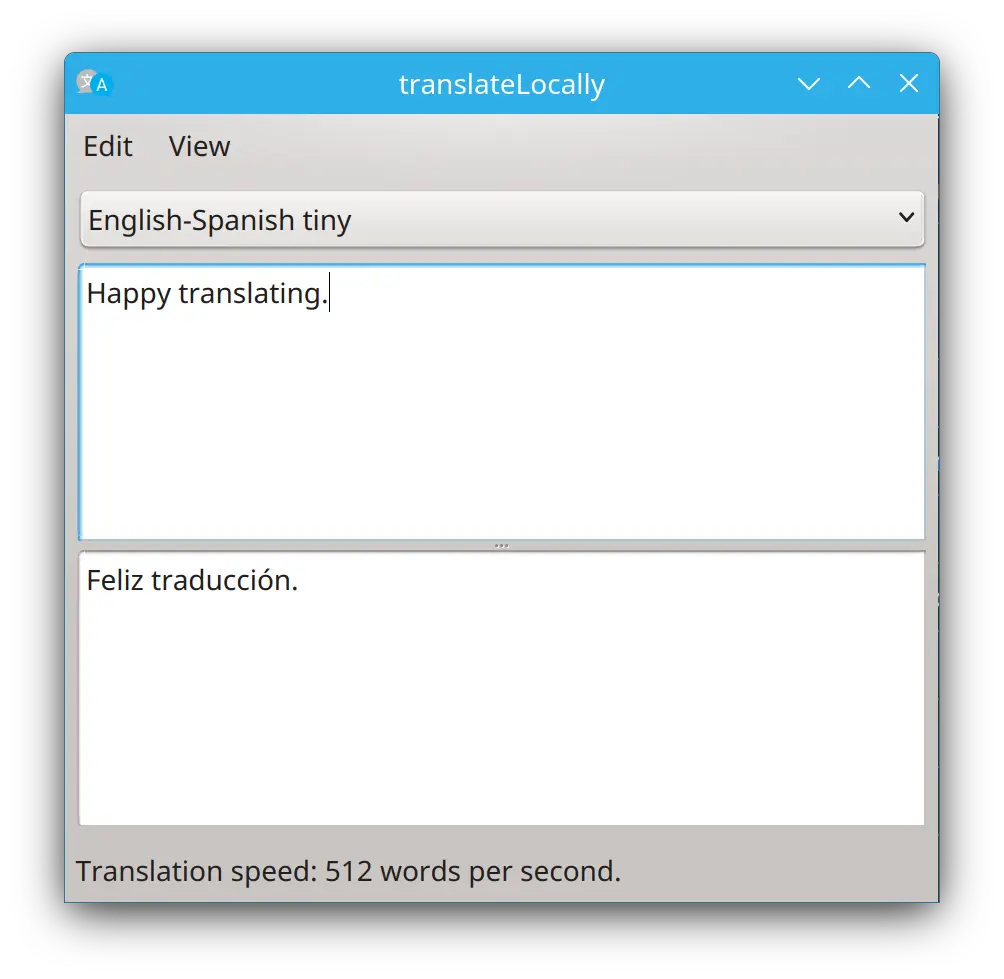
Vous en avez assez de jongler entre Git et YAML pour mettre à jour votre site Next.js, Astro, Hugo ou Nuxt ? Simplifiez-vous la vie en installant un CMS convivial directement sur GitHub à l’aide de Pages CMS, la nouvelle coqueluche des gestionnaires de contenu pour les sites statiques.
Avec cet outil, fini les prises de tête avec les fichiers de configuration et les commits laborieux puisqu’il s’intègre de manière transparente à votre dépôt GitHub, vous permettant de gérer votre contenu directement depuis une interface intuitive. Ainsi, vous pourrez personnaliser vos types de contenu, vos vues, votre recherche… et côté édition, vous profiterez d’un éditeur de texte riche avec coloration syntaxique, d’un glisser-déposer pour vos fichiers, d’une recherche full-text hyper rapide… Le tout saupoudré de fonctionnalités bien pensées comme la planification de mises à jour ou le contrôle d’accès granulaire.
Pages CMS est 100% gratuit, open source et vous pouvez l’utiliser en ligne ou l’auto-héberger sans débourser un centime. En quelques clics, vous créez votre compte, connectez votre dépôt GitHub et hop, vous voilà paré pour dompter votre contenu comme un pro. C’est beau, la vie de développeur, non ? 🌈
Bon, je vous vois venir avec vos grands chevaux. « Mais est-ce que ça va pas transformer mon dépôt en usine à gaz ?« . Que nenni ! Pages CMS est une simple appli front-end avec des fonctionnalités backend limitées. Ça tourne sur Cloudflare Pages et ça n’interfère en rien avec votre code. Et si vous voulez garder la main, vous pouvez toujours passer par Git pour les modifications sensibles.
En parlant de Git justement, je vous rassure tout de suite : Pages CMS n’a pas accès à TOUS vos dépôts. Il utilise le flux OAuth de GitHub pour des autorisations ciblées. Et vos tokens d’accès ne sont jamais stockés côté serveur. Votre code reste votre précieux, comme dirait Gollum.
Pour l’installer, rendez-vous sur pagescms.org, créez votre compte en deux clics et connectez votre dépôt GitHub. Et voilà, vous êtes prêt à dompter votre contenu. Et pour les adeptes de l’auto-hébergement, comptez 10 petites minutes pour déployer Pages CMS sur votre compte Cloudflare.
Sur ce, je vous laisse, j’ai du contenu à publier moi. Allez, tchô la compagnie ! 👋