
Ce week end, je vous ai expliqué comment balancer vos backups automatiquement sur Amazon S3, mais si voulez faire certaines choses manuellement, il existe l’outil parfait pour ça : S3cmd.
S3cmd, c’est tout simplement une interface en ligne de commande pour piloter son Amazon S3.
Pour l’installer (ubuntu / debian), faites (sinon, les binaires sont là) :
sudo apt-get s3cmd
Ensuite, il faut le configurer :
s3cmd –configure
Suivez les instructions. En gros, vous avez besoin de votre clé d’accès et de votre clé secrète S3. Pour savoir comment les récupérer, je vous invite à lire la partie sur IAM dans ce tuto.
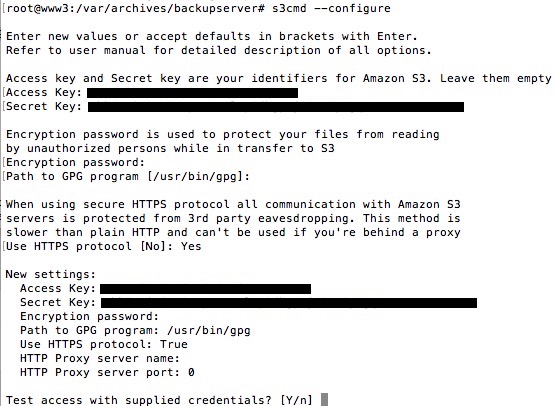
Le processus de config vous demandera aussi un mot de passe pour chiffrer les fichiers envoyés vers le S3. Ce n’est pas obligatoire, à vous de voir. Par contre, je vous recommande vivement d’accepter l’utilisation du protocole HTTPS (« Use HTTPS protocol : Yes ») pour que les fichiers soient transmis au serveur S3 avec un minimum de sécurité. Si ce sont des fichiers publics, vous pouvez passer en HTTP, ce sera un peu plus rapide.
Voilà, maintenant que c’est configuré, on va pouvoir jouer. Première étape, lister les buckets présents sur Amazon S3 :
s3cmd ls
Ensuite, pour créer un nouveau bucket :
s3cmd mb s3://monbucket
Maintenant on va mettre des trucs dedans avec le paramètre put :
s3cmd put fichier.jpg s3://monbucket
Pour y balancer carrément un répertoire, il faut utiliser le paramètre -r
s3cmd put -r monrepertoire s3://monbucket
Attention, petite subtilité, si vous voulez uploader uniquement le contenu de ce répertoire (et pas le répertoire lui-même), pensez à mettre un / après le nom :
s3cmd put -r monrepertoire/ s3://monbucket
Maintenant pour vérifier que tout est bien en place sur le bucket, il suffit de faire un petit ls
s3cmd ls s3://monbucket
Pour connaitre la taille de votre bucket, faites un
s3cmd du s3://monbucket
Pour récupérer l’un de ces fichiers, utilisons maintenant get
s3cmd get s3://monbucket/fichier.jpg
Pour copier un fichier d’un endroit à un autre du bucket (ou de 2 buckets différents), faites :
s3cmd cp s3://monbucket/fichier.jpg s3://monbucket/autre_dossier/fichier.jpg
Pour déplacer un fichier, même principe :
s3cmd mv s3://monbucket/fichier.jpg s3://monbucket/autre_dossier/fichier.jpg
Voilà, maintenant vous maitrisez S3cmd. Maintenant si vous voulez supprimer un truc (fichier ou dossier), il faut faire :
s3cmd del s3://monbucket/fichier.jpg
Vous pouvez aussi utiliser l’alias « rm » à la place de « del ».
Sachez enfin que pour supprimer totalement un bucket il faut que ce dernier soit vide. Pensez donc bien à en supprimer tout le contenu avant de supprimer le bucket en lui-même. Voici comment supprimer un bucket vide :
s3cmd rb s3://monbucket
Si vous placez des choses dans Glacier comme je vous ai expliqué sur mon tuto précédent, vous pouvez aussi restaurer des fichiers à partir de celui-ci avec la commande
s3cmd restore s3://monbucket/fichier.jpg
Si vous avez besoin de synchroniser un répertoire local avec un répertoire S3, utilisez la commande sync. Elle utilisera les MD5 des fichiers pour savoir quoi envoyer et quoi mettre à jour sur votre S3 ou en local sur votre disque dur.
s3cmd sync monrepertoire s3://monbucket/monrepertoire
Et voilà.. Rien de plus simple à utiliser en fait, alors pourquoi s’en passer ?
S3cmd propose aussi des choses un peu plus évoluées pour gérer les droits d’accès, jouer avec les archives splittées, régler le cycle de vie des buckets, ou encore publier sur le web mais je n’ai pas encore testé toute cette partie, donc je vous invite à vous pencher sur la doc ;-).