Local Deep Research - L'assistant de recherche IA open-source qui cite ses sources
Il y a un outil que j’aime bien utiliser en ce moment, c’est la fonctionnalité Deep Research d’OpenAI. Cela me permet de creuser différents sujets tout en obtenant des sources fiables puisque cette fonctionnalité se repose sur des recherches hyper poussées et itératives, contrairement aux modèles IA classiques qui peuvent parfois inventer des références comme un politicien en campagne électorale.
Le truc c’est que ça coûte du pognon de diiiiingue et que tout le monde ne peut malheureusement pas en profiter. Un abonnement ChatGPT Plus à 20$ par mois minimum, et encore, c’est limité en nombre de recherches approfondies.
Heureusement, il existe une alternative open source à héberger vous-même qui s’appelle “Local Deep Research” et qui fait tout pareil en se reposant sur des sources en ligne type Wikipedia, arXiv, PubMed, DuckDuckGo, etc… Ces informations collectées sont ensuite traités par des LLM, soit dans le cloud comme ChatGPT ou Claude, ou en local avec Ollama (on peut utiliser le modèle Mistral par exemple).
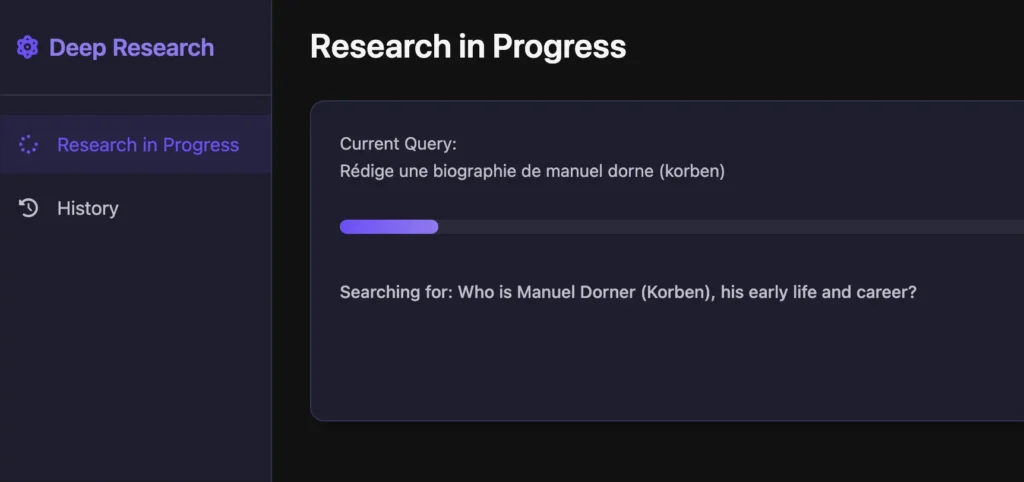
Interface web de Local Deep Research avec un exemple de recherche
L’intérêt de ce genre d’outils, c’est qu’il fonctionne comme un Sherlock Holmes numérique : il pose une première question, analyse les résultats, puis génère automatiquement des questions de suivi pour approfondir et vérifier les informations. Ça permet d’éliminer les hallucinations et les fausses sources qu’on peut parfois avoir avec des LLM traditionnels et ainsi avoir de la vraie information bien sourcée, avec les citations et les liens si on veut ensuite vérifier.
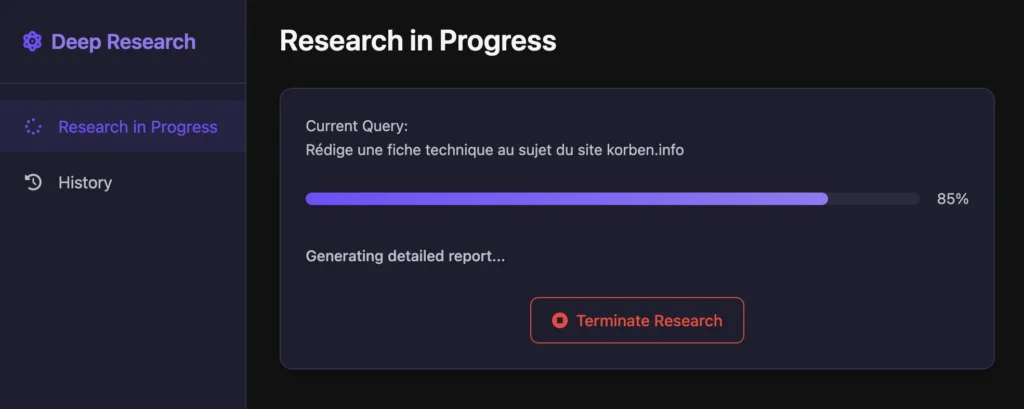
L’outil a quelques avantages qui font la différence avec d’autres outils du même style :
- Confidentialité totale : tout peut tourner localement sur votre machine
- Multi-sources intelligentes : le système choisit les meilleures sources selon la requête
- Vérification des citations : adieu les références bidon
- Recherche dans vos documents personnels : grâce au système RAG intégré
- Interface web intuitive : historique des recherches, exports PDF, etc.
Voici comment installer Local Deep Research. Tout d’abord, clonez le dépôt :
git clone https://github.com/LearningCircuit/local-deep-research.git
cd local-deep-research
Ensuite, créez et activez l’environnement virtual (j’utilise uv) :
# Créer un environnement virtuel
uv venv
# Activer l'environnement virtuel
source .venv/bin/activate # Sur macOS/Linux
# .venv\Scripts\activate # Sur Windows
Puis installez les dépendances comme ceci :
# Installer les dépendances à partir du fichier requirements.txt
uv pip install -r requirements.txt
Récupérez éventuellement le modèle Mistral à l’aide d’Ollama si ce n’est pas encore fait :
ollama pull mistral
Puis créez le fichier de conf et éditez le pour y mettre vos clés API :
cp .env.template .env
Côté performances, sachez que l’outil n’est pas trop gourmand si vous utilisez les LLMs en cloud. En revanche, pour une utilisation 100% locale avec Ollama, comptez au minimum 16Go de RAM et un GPU décent pour faire tourner Mistral confortablement. Les temps de traitement varient entre 1-5 minutes selon la complexité de la recherche.
Le truc vraiment cool, c’est que vous pouvez aussi ajouter vos propres collections de documents pour les inclure dans vos recherches. Imaginez pouvoir interroger vos PDF, notes et documents Word avec la même puissance d’analyse ! Pour cela, créez les répertoires nécessaires pour le stockage des documents comme ceci :
mkdir -p local_search_files/research_papers
mkdir -p local_search_files/personal_notes
Puis créez le fichier local_collections.py à la racine du projet avec le contenu suivant pour y indexer vos documents :
# local_collections.py
import os
from typing import Dict, Any
# Registre des collections de documents locaux
LOCAL_COLLECTIONS = {
# Collection de papiers de recherche
"research_papers": {
"name": "Research Papers",
"description": "Academic research papers and articles",
"paths": [os.path.abspath("local_search_files/research_papers")],
"enabled": True,
"embedding_model": "all-MiniLM-L6-v2",
"embedding_device": "cpu",
"embedding_model_type": "sentence_transformers",
"max_results": 20,
"max_filtered_results": 5,
"chunk_size": 800,
"chunk_overlap": 150,
"cache_dir": ".cache/local_search/research_papers"
},
# Collection de notes personnelles
"personal_notes": {
"name": "Personal Notes",
"description": "Personal notes and documents",
"paths": [os.path.abspath("local_search_files/personal_notes")],
"enabled": True,
"embedding_model": "all-MiniLM-L6-v2",
"embedding_device": "cpu",
"embedding_model_type": "sentence_transformers",
"max_results": 30,
"max_filtered_results": 10,
"chunk_size": 500,
"chunk_overlap": 100,
"cache_dir": ".cache/local_search/personal_notes"
}
}
Quelques paramètres importants à connaître dans le fichier config.py :
- DEFAULT_MODEL : change “mistral” si tu veux utiliser un autre modèle Ollama
- DEFAULT_TEMPERATURE : 0.7 par défaut, baisse à 0.1 pour des résultats plus factuels
- MAX_SEARCH_RESULTS : augmente jusqu’à 100 pour des recherches plus exhaustives
- search_tool : “auto” sélectionne intelligemment la source, ou spécifie “wiki”, “arxiv”, etc.
Enfin, lancez l’outil qui sera alors accessible sur le port 5000 sur votre IP local via un navigateur.
python app.py
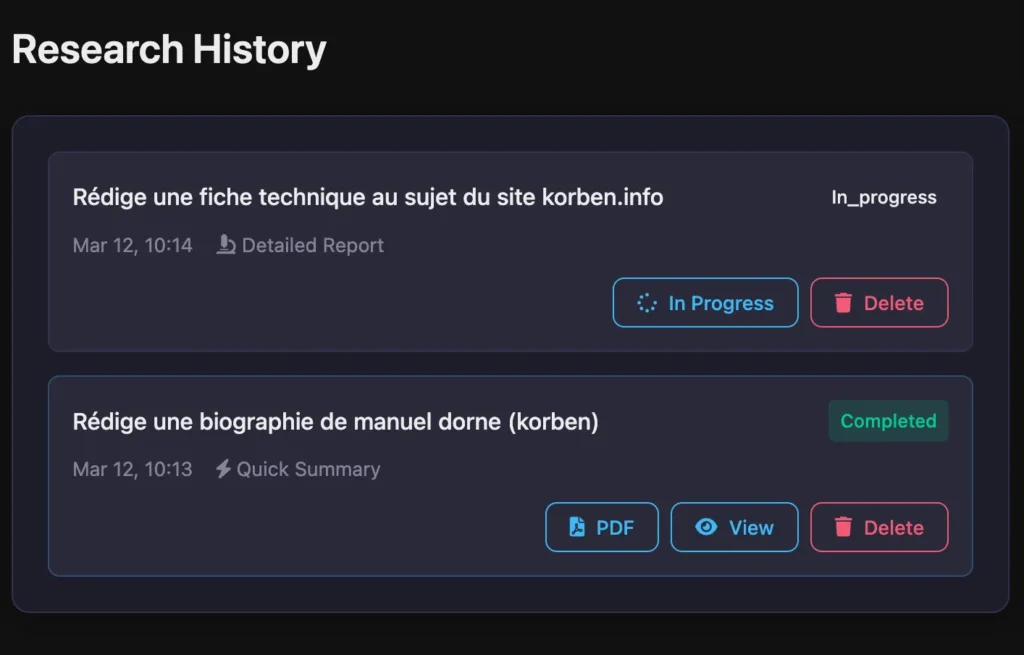
Dashboard avec historique des recherches
Vous pourrez alors formuler une demande et l’outil se mettra en route pour vous pondre un rapport le plus détaillé possible sur ce que vous avez demandé. Le processus est d’ailleurs fascinant à observer… il commence par une recherche initiale, analyse les résultats, puis génère automatiquement des questions de suivi pour approfondir. Par exemple, si vous demandez “je veux les dernières avancées en fusion énergétique”, il peut ensuite chercher de lui-même “investissements privés en fusion nucléaire 2024” ou “délais commercialisation réacteurs fusion”.
Bon, par contre, je vous le dis tout de suite, le projet est encore un peu jeune et très anglophone donc les résultats sont loin d’être parfaits, mais ça peut quand même dépanner si vous cherchez des infos précises et bien sourcées sans débourser un centime. Et pour les développeurs parmi vous, c’est un projet open-source, donc n’hésitez pas à contribuer pour l’améliorer ou l’adapter à vos besoins !
Blogueurs, influenceurs, créateurs de contenus... Si comme moi vous vivez de votre créativité en ligne, vous méritez ce qu'il y a de mieux pour votre activité !

Laissez-moi vous présenter l'Offre Unique de o2switch : LA solution idéale pour propulser votre site ou blog. Avec son espace disque illimité et ses bases de données sans restriction, publiez autant de contenus que vous voulez sans vous soucier des limites !
Gérez votre WordPress comme un pro grâce aux outils exclusifs et à l'interface cPanel ultra simple. Soyez serein avec un nom de domaine offert, des sauvegardes quotidiennes de vos précieux contenus et un hébergement français sécurisé. Et s'il y a un souci, le support technique est là pour vous 24/7 !
Vous voulez le meilleur ? C'est seulement 4,2 € HT/mois. Oui oui, c'est tout ! Alors n'attendez plus et offrez à votre site le tremplin qu'il mérite. Votre communauté n'attend que ça !