La bibliothèque JavaScript de visualisation de PDF développée par Mozilla, connue sous le nom de PDF.js, est au centre d’une nouvelle découverte de sécurité assez préoccupante ! Une faille dans le code de rendu des polices permet à un attaquant d’exécuter du JavaScript arbitraire simplement en ouvrant un PDF malveillant. Et attention, cela affecte toutes les applications utilisant PDF.js, y compris Firefox, certains éditeurs de code et navigateurs de fichiers. Aïe aïe aïe !
En gros, lorsque PDF.js affiche une police spéciale, il convertit la description des glyphes en instructions pour dessiner ces glyphes. Cependant, un hacker mal intentionné peut injecter son propre code dans la description de la police, résultant en l’exécution de ce code par le navigateur.
La vulnérabilité, estampillée CVE-2024-4367, repose donc sur une manipulation des commandes de rendu de polices. La commande transform utilisant fontMatrix est exploitée pour insérer du code JavaScript puis PDF.js compile dynamiquement les descriptions de polices pour optimiser les performances. Normalement, ce tableau contient uniquement des nombres, toutefois, cette faille permet d’y injecter des chaînes de caractères. Et en insérant du code JavaScript dans ce tableau, il est possible de déclencher du code lors du rendu d’une police.
Un exploit bien forgé permettrait diverses attaques telles que l’exécution de code arbitraire, le vol de données, ou même la prise de contrôle complète du système via des attaques XSS ou l’exécution de code natif. La vulnérabilité touche actuellement les versions de PDF.js inférieures à 4.2.67.
Selon les chercheurs de Codean Labs, cette vulnérabilité affecte non seulement les utilisateurs de Firefox (<126), mais également de nombreuses applications web et basées sur Electron utilisant indirectement PDF.js pour la fonctionnalité d’aperçu. Ils soulignent également que cette faille exploite une partie spécifique du code de rendu de la police, un segment que les développeurs devraient vérifier attentivement.
Bref, pensez à mettre à jour PDF.js vers une version supérieure à la 4.2.67 et à mettre à jour vos outils vers des version égales ou supérieures à Firefox 126, Firefox ESR 115.11 et Thunderbird 115.11.
Imaginez télécharger un modèle d’IA apparemment inoffensif sur une plateforme de confiance comme Hugging Face et découvrir qu’il ouvre en fait une porte dérobée permettant à des attaquants de prendre le contrôle de votre système ! C’est le risque que pose la faille critique CVE-2024-34359, découverte récemment dans le célèbre package Python llama-cpp-python.
Ce package très utilisé permet d’intégrer facilement des modèles d’IA écrits en C++ dans des projets Python. Pour cela, il utilise la bibliothèque de templates Jinja2 qui est capable de faire un rendu dynamique du HTML à partir des données. Une lib surpuissante mais potentiellement risquée si c’est mal configuré !
Et c’est justement là que le bât blesse. Le package llama-cpp-python utilise Jinja2 pour traiter les métadonnées des modèles au format .gguf, mais sans activer les protections nécessaires comme le bac à sable. Du coup, en injectant un template malicieux dans les métadonnées d’un modèle, un pirate peut exécuter du code arbitraire sur le système hôte !
Les dégâts potentiels sont énormes : vol de données, prise de contrôle totale, interruption de services… Surtout que les systèmes IA manipulent souvent des données ultra sensibles. Et vu la popularité de llama-cpp-python, l’impact est massif : plus de 6000 modèles vulnérables rien que sur Hugging Face ! Selon un article détaillé de Checkmarx, cette faille permet des attaques de la chaîne d’approvisionnement, où un acteur malveillant peut injecter du code dans un modèle téléchargé et redistribuer ce modèle compromis pour attaquer les développeurs d’IA.
Découverte par Patrick Peng (alias retro0reg), cette vulnérabilité repose comme je vous l’expliquait sur une mauvaise implémentation du moteur de templates. Cette faille de score CVSS critique de 9.7, permet l’injection de template côté serveur, conduisant à une exécution de code à distance (RCE). Un proof-of-concept a même été publié sur Hugging Face, démontrant comment un modèle compromis peut exécuter du code arbitraire lorsqu’il est chargé ou lors d’une session de chat.
Cela met en lumière un problème plus large : la sécurité des systèmes d’IA est intimement liée à celle de leur chaîne logicielle. Une vulnérabilité dans une dépendance tierce peut compromettre tout un système. Il faut donc redoubler de vigilance à tous les niveaux. Les modèles d’IA étant souvent utilisés au sein de projets critiques et manipulant des volumes importants de données sensibles, la moindre faille peut avoir des conséquences catastrophiques.
Mais rassurez-vous, une solution existe ! La version 0.2.72 de llama-cpp-python corrige le tir en ajoutant une validation des entrées et un bac à sable robuste autour de Jinja2. Si vous utilisez une version antérieure, la mise à jour est plus que recommandée.
Comment savoir si vos modèles sont touchés ? Regardez s’ils utilisent :
Le package llama-cpp-python en version < 0.2.72
Le format de fichier .gguf
Des templates Jinja2 dans les métadonnées
Si c’est le cas, passez immédiatement à la 0.2.72 ! Vous pouvez aussi auditer le code de vos modèles et regarder les permissions avec vos yeux de lynx.
Bref, comme d’hab, une petite faille peut vite tourner au désastre
Vous utilisez probablement le GPS tous les jours sans y penser, que ce soit sur votre smartphone, dans votre voiture ou même dans un avion. Cette technologie de positionnement par satellites, et ses cousines comme GLONASS, Galileo et Beidou, sont devenues tellement courantes qu’on en oublierait presque qu’elles sont vulnérables. Et quand je dis vulnérables, je ne parle pas d’un bug ou d’un plantage logiciel, non. Je parle de menaces bien réelles qui peuvent rendre votre GPS complètement dingue !
Vous voyez, le GPS repose sur des signaux radio ultra faibles émis par des satellites à des milliers de kilomètres. Pour vous donner une idée, c’est un peu comme si vous essayiez d’entendre quelqu’un vous chuchoter quelque chose depuis l’autre bout d’un stade pendant un concert de rock ! Autant dire que c’est le bordel pour entendre quoi que ce soit.
Du coup, pas besoin d’être un génie pour comprendre qu’il est facile de noyer le signal GPS dans un gros brouhaha radio. C’est ce qu’on appelle le brouillage. Avec quelques watts seulement, on peut rendre le GPS inutilisable dans un rayon de plusieurs kilomètres ! Pas besoin d’un doctorat en électronique, un petit bricolage fait maison peut suffire. Évidemment, c’est complètement illégal, mais ça n’empêche pas certains de s’amuser à le faire.
Mais pourquoi brouiller le GPS ? Eh bien, en cas de conflit par exemple, c’est bien pratique pour empêcher l’ennemi de savoir où il est et où tirer ses missiles et ses drones. C’est d’ailleurs ce qui se passe en ce moment autour de l’Ukraine. Des zones de brouillage apparaissent régulièrement, rendant la navigation aérienne hasardeuse.
Mais le brouillage peut aussi servir à des fins moins guerrières. Tenez, en Chine, il paraît que des boîtes de pub brouillent le GPS des drones de leurs concurrents pendant des shows aériens pour leur faire perdre le contrôle et ruiner le spectacle ! De la concurrence de haut vol, sans mauvais jeu de mots.
Et les dégâts collatéraux dans tout ça ?
Parce que mine de rien, on ne dépend pas du GPS uniquement pour savoir si on doit tourner à gauche ou à droite au prochain croisement. Les réseaux de téléphonie mobile s’en servent également pour synchroniser leurs antennes relais. Ainsi, quand le GPS déconne, c’est toute la 4G/5G qui peut partir en vrille !
Mais si vous trouvez que le brouillage c’est déjà costaud, attendez de découvrir le leurrage ! Là, on passe au niveau supérieur. Le leurrage, c’est carrément une technique qui permet d’envoyer de faux signaux GPS pour faire croire à votre récepteur qu’il est ailleurs. Un peu comme si un petit rigolo changeait les panneaux sur la route pour vous faire croire que vous allez vers le sud de la France, alors que vous roulez vers le Nord.
Alors bien sûr, générer un faux signal GPS crédible, c’est autrement plus coton que simplement brouiller la fréquence. Il faut recréer toute une constellation de satellites virtuels avec les bons timings, les bonnes orbites, cohérents entre eux. Un vrai boulot d’orfèvre ! Mais une fois que c’est au point, imaginez le potentiel de nuisance ! Vous pourriez faire atterrir un avion de ligne à côté de la piste. Téléguidez un drone militaire en territoire ennemi ou envoyer un navire s’échouer sur des récifs. Ça fait froid dans le dos…
Heureusement, il existe des parades pour durcir les récepteurs GPS contre ces attaques : Utiliser des antennes directionnelles qui filtrent les signaux ne venant pas du ciel. Analyser en détail les signaux pour repérer les incohérences et les satellites suspects. Recouper avec d’autres capteurs comme les centrales inertielles. La version militaire du GPS dispose déjà de pas mal de protections dont du chiffrement.
Mais pour le GPS grand public dans nos smartphones et nos bagnoles, on est encore loin du compte. À part quelques modèles haut de gamme, la plupart gobent à peu près tout et n’importe quoi tant que ça ressemble à un signal GPS et il va falloir que ça change, et vite !
Scott Manley, un expert en la matière que vous connaissez peut-être pour ses vidéos sur les fusées, aborde en profondeur ces questions dans une vidéo bien documentée sur le sujet. Non seulement il analyse les risques de brouillage et de leurrage, mais il examine aussi les contre-mesures possibles, comme l’utilisation d’antennes directionnelles et l’analyse détaillée des signaux pour repérer d’éventuelles incohérences. Je vous mets la vidéo ici, ça vaut le coup d’œil :
On a beau être fan des nouvelles technos qui nous rendent la vie plus facile, faut quand même garder à l’esprit qu’elles ont leurs failles et leurs limites. Ça ne veut pas dire qu’il faut revenir à la bonne vieille carte Michelin et à la boussole, mais un petit cours de rattrapage en navigation à l’ancienne, ça ne ferait pas de mal !
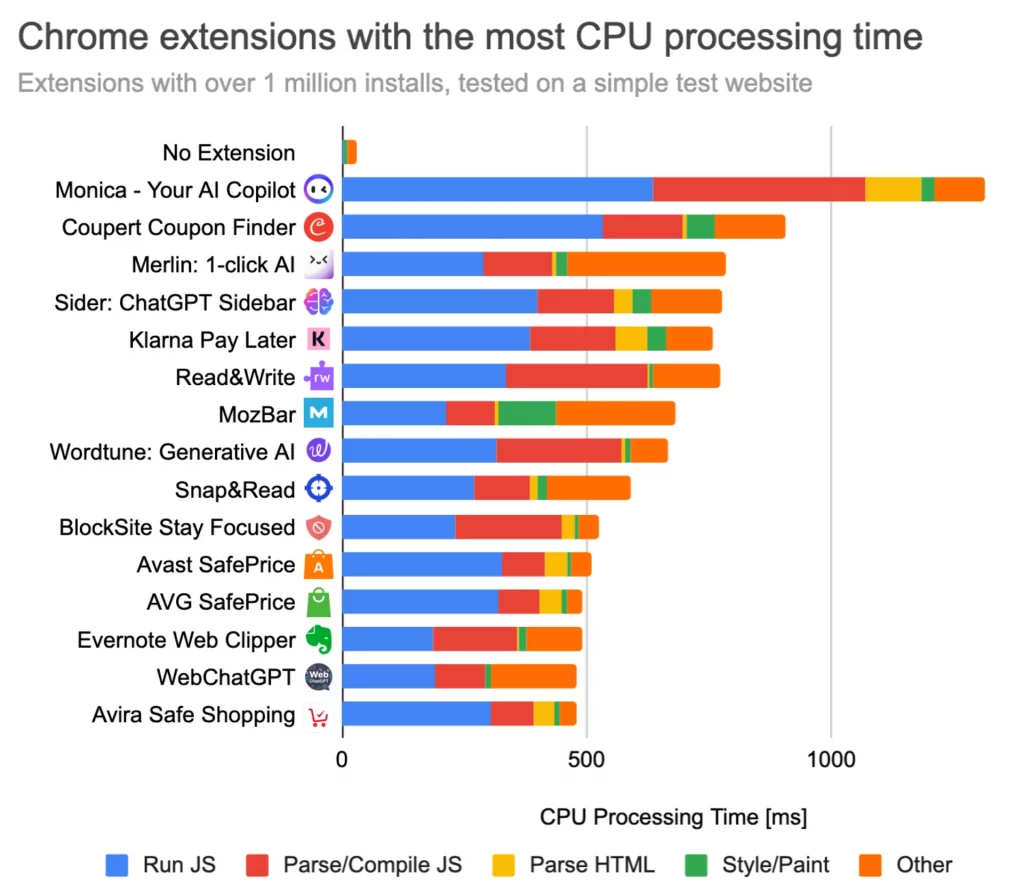
On s’en doutait, mais là c’est prouvé scientifiquement : Les extensions Chrome peuvent sérieusement ralentir vos séances de surf !
C’est en tout cas ce que révèlent les tests menés par la bande de geeks de DebugBear qui ont passé au crible les 5000 extensions Chrome les plus populaires pour voir l’impact sur les performances. Et c’est décevant… Prenez par exemple Monica, un outil IA avec ses 2 millions d’utilisateurs. Et bien elle rajoute tranquillement 1,3 seconde de temps de traitement sur chaque page, même les plus basiques ! Pas glop…
Un autre exemple concerne Honey, un outil qui propose des coupons de réduction et qui compte 20 millions d’utilisateurs. Quand vous surfez sur un site de shopping comme Ikea, ce petit malin s’active et vous colle 1,5 seconde de CPU en plus. Bonjour l’addition !
Mais le pire du pire, c’est MaxAI et ses 800 000 utilisateurs. Cet outil infernal ajoute carrément 2,3 secondes de traitement à chaque page ! What the heck ? On n’est pas tous équipés d’un super GPU quantique de la mort pour compenser le laxisme des dev…
Notons aussi que « Superagent – Automatic cookie consent » cause plus de 4 secondes de traitement par page. Certains programmes de récompenses pour les compagnies aériennes présentent un impact similaire, ajoutant encore plus de délai lorsqu’ils sont actifs.
Heureusement, la plupart des extensions ne sont pas si terribles. 86% ont un impact négligeable, avec moins de 50 millisecondes de temps CPU supplémentaire. Ouf ! Par contre, il y en a quand même 1,7% qui dépassent allègrement la demi-seconde et ça c’est pas cool.
En creusant un peu, on voit que pas mal d’extensions VPN ou de gestionnaires de mots de passe ralentissent sévèrement le chargement des pages. Forcément, elles font transiter les données par des serveurs souvent lents à l’autre bout du monde, donc ça aide pas…
Mais il y a quand même une bonne nouvelle dans ce merdier ! Les bloqueurs de pubs, eux, accélèrent carrément la navigation. Normal, ils empêchent le chargement de tout un tas de contenus indésirables. uBlock Origin, l’un des plus populaires avec ses 37 millions d’utilisateurs, fait fondre le temps de traitement de 57 secondes à moins de 4 secondes sur les sites pleins de pubs ! Magique, mais pensez quand même à le débloquer sur mon site pour me soutenir ou à rejoindre mon Patreon si un jour l’un de mes articles vous a aidé et que vous appréciez mon boulot !
Et au niveau des données téléchargées, ça change la vie. Sans bloqueur, un site bourré de pubs pèse 41 Mo. Avec uBlock Origin, on tombe à moins de 3 Mo. Impressionnant ! Bon après, AdBlock et AdBlock Plus, je vous les déconseille car ils sont moins efficaces. Peut-être à cause du programme des « publicités acceptables » qui peut être désactivée pour améliorer les performances ? Va savoir…
Bref, avis aux développeurs d’extensions : optimisez votre code s’il vous plait ! Chargez le strict minimum, faites tourner vos scripts après le chargement de la page, pas avant. Et laissez les gens tranquilles, n’activez pas vos outils sur tous les sites par défaut quand ça n’a pas lieu d’être !
Google devrait aussi mettre un peu la pression et promouvoir les extensions légères et bien foutues car les gros scripts bien lourds qui se lancent de partout, ça va bien 5 minutes !
Bref, c’est le printemps (même s’il pleut tout le temps), alors profitez en pour faire le tri dans vos extensions ! Virez celles qui ne vous servent à rien et qui bouffent de la ressource comme pas permis ou à minima, désactivez-les quand vous n’en avez pas besoin. Votre navigateur vous dira merci !
Vous êtes-vous déjà retrouvé frustré par les limites de tokens lorsque vous demandiez à ChatGPT de résumer de longs textes ? Ou découragé par les coûts élevés de l’API GPT-3.5/4 malgré d’excellents résultats ? Si c’est le cas, LLMLingua est fait pour vous !
Développé par des chercheurs de Microsoft, LLMLingua-2 est un outil révolutionnaire de compression de prompts qui permet d’accélérer l’inférence des grands modèles de langage (LLM) comme GPT-3 et GPT-4. Grâce à des techniques avancées d’identification et de suppression des tokens non essentiels, il peut réduire jusqu’à 20 fois la taille des prompts, tout en préservant les performances des modèles.
Que vous soyez un développeur cherchant à optimiser ses coûts d’API ou un utilisateur souhaitant dépasser les limites de contexte, LLMLingua vous offre de nombreux avantages :
💰 Réduction des coûts : En compressant à la fois les prompts et les réponses générées, LLMLingua permet de réaliser des économies significatives sur votre facture d’API.
📝 Support de contextes étendus : Fini le casse-tête du « perdu au milieu » ! LLMLingua gère efficacement les longs contextes et booste les performances globales.
⚖️ Robustesse : Pas besoin d’entraînement supplémentaire pour les LLM. LLMLingua fonctionne de manière transparente.
🕵️ Préservation des connaissances : Toutes les informations clés des prompts originaux, comme l’apprentissage en contexte et le raisonnement, sont conservées.
📜 Compression du cache KV : Le processus d’inférence est accéléré grâce à l’optimisation du cache clé-valeur.
🪃 Récupération complète : GPT-4 est capable de reconstituer l’intégralité des informations à partir des prompts compressés. Bluffant !
Prenons un exemple simple et imaginons que vous vouliez compresser le prompt suivant avec LLMLingua :
python from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
prompt = "Sam a acheté une douzaine de boîtes contenant chacune 30 surligneurs, pour 10 $ chacune..."
compressed_prompt = llm_lingua.compress_prompt(prompt)
print(compressed_prompt)
Et voilà le travail ! En quelques lignes de code, vous obtenez un prompt compressé prêt à être envoyé à votre modèle favori :
Sam acheté boîtes contenant chacune 30 surligneurs, 10 $ chacune.
Avec un taux de compression de 11,2x, le nombre de tokens passe de 2365 à seulement 211 ! Et ce n’est qu’un début. Sur des exemples plus complexes comme les prompts Chain-of-Thought, LLMLingua maintient des performances similaires avec un taux de compression allant jusqu’à 20x.
Alors bien sûr, pour l’avoir bien testé, faut quand même comprendre que vous n’obtiendrez pas forcement un résultat identique entre le prompte compressé et celui non compressé mais pour un gain de 60 / 70 voire 80%, le résultat généré à partir du prompt compressé reste précis à hauteur de 70 / 80 %, ce qui est très bien.
Pour démarrer avec LLMLingua, rien de plus simple. Installez le package avec pip :
pip install llmlingua
Puis laissez libre cours à votre créativité ! Que vous soyez un adepte du Retrieval Augmented Generation (RAG), des réunions en ligne, du Chain-of-Thought ou même du code, LLMLingua saura répondre à vos besoins. De nombreux exemples et une documentation complète sont à votre disposition pour vous guider.
Perso, je l’ai testé sur de longs prompts que j’avais dans mes scripts, avec Claude3 d’ailleurs et pas ChatGPT et le résultat est top !