Depuis que ChatGPT a catapulté l’IA générative sur le devant de la scène il y a plus d’un an, des milliers de nouvelles apps IA grand public ont vu le jour. Ça va des générateurs de vidéos délirants aux assistants de productivité boostés à l’IA, en passant par des outils créatifs et même des compagnes virtuelles !
Andreesen Horowitz a épluché pour vous les data de trafic web d’un tas de services IA pour identifier le top 50 des apps IA les plus populaires du moment, histoire de faire le tri dans cette jungle.
Et devinez quoi ?
En à peine 6 mois, plus de 40% des boîtes dans le classement sont des petits nouveaux ! Ça bouge à une de ces vitesses dans le monde de l’IA…
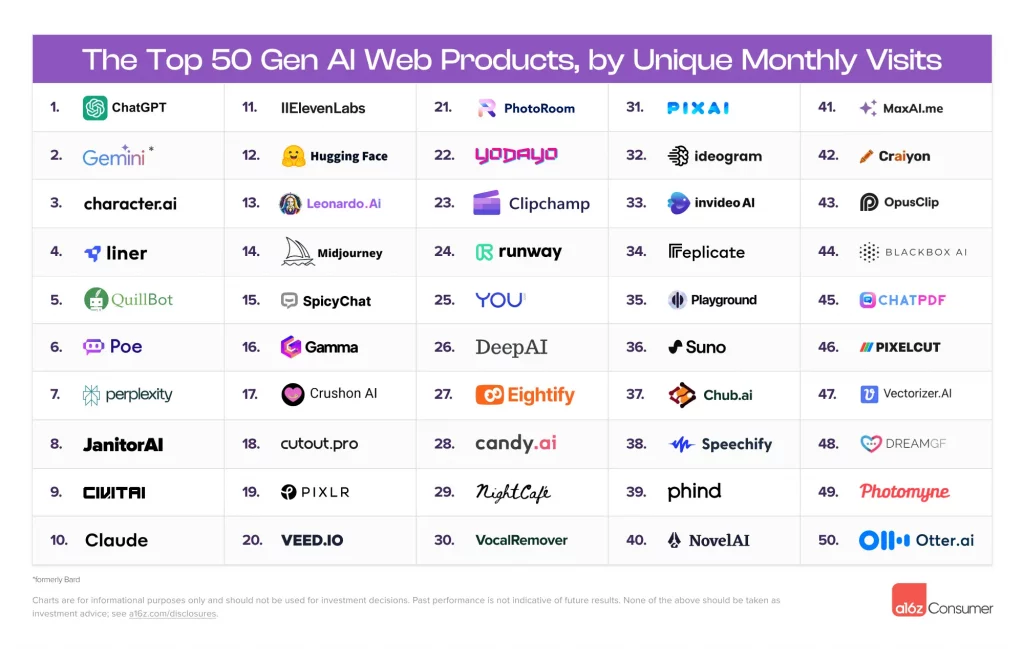
Alors ok, les poids lourds comme ChatGPT, Midjourney ou Character.AI trustent toujours le haut du panier côté fréquentation. Mais de nouvelles catégories émergent, comme les outils de productivité (recherche, prise de notes, résumé de docs…) et même la musique ! Vous avez déjà essayé Suno ? Cette app permet de générer des chansons complètes à partir d’un simple texte. Bluffant !
Côté apps mobiles, c’est un peu la foire aux assistants façon ChatGPT et aux créateurs d’avatars. Forcément, avec toutes les photos qu’on a dans nos smartphones, y a de quoi alimenter les IA. Mais là où ça devient intéressant, c’est quand on creuse les usages spécifiques au mobile : les claviers IA pour écrire ses textos, les scanners de devoirs pour les étudiants flemmards, les profs de langues virtuels…

Plein de ces apps à succès viennent de studios basés à Istanbul ou Milan ! Les gars maîtrisent l’art de pondre des apps IA addictives et qui rapportent beaucoup pognon. Du genre Remini, l’outil d’amélioration de photos, qui a levé 155 millions de dollars ! 🤑
Bref, une chose est sûre, cette nouvelle génération d’apps IA est en train de bouleverser nos usages à vitesse grand V. Elles nous rendent plus créatifs, plus productifs… et parfois un peu accros aussi, faut bien l’avouer ! 😅 Mais honnêtement, quand je vois tout ce qui est possible aujourd’hui grâce à l’IA générative, j’ai hâte de découvrir la suite.